
摘要:為了提高語音識別效率及對環境的依賴性,文章對語音識別算法部分和硬件部分做了分析與改進,采用ARMS3C2410微處理器作為主控制模塊,采用UDA1314TS音頻處理芯片作為語音識別模塊,利用HMM聲學模型及Viterbi算法進行模式訓練和識別,設計了一種連續的、小詞量的語音識別系統。實驗證明,該語音識別系統具有較高的識別率和一定程度的魯棒性,實驗室識別率和室外識別率分別達到95.6%,92.3%。
關鍵詞:語音識別;嵌入式系統;Hidden Markov Models;ARM;Viterbi算法
0 引言
嵌入式語音識別系統是應用各種先進的微處理器在板級或是芯片級用軟件或硬件實現的語音識別。嵌入式技術與語音識別技術相結合,能使人們甩掉鍵盤,通過語音命令對智能化終端進行操作,人與智能化終端之間的這種自然快捷的交互方式有助于提高人機交互的效率,以適應嵌入式平臺存儲資源少,實時性要求高的特點,增強人對智能化設備的控制,同時,在語音識別技術發展過程中又以HMM的廣泛應用為特點。該算法通過對大量語音數據進行數據統計,建立識別詞條的統計模型,然后從待識別語音中提取特征,與這些模型匹配,通過比較匹配概率,以獲得識別結果,通過建立大量的語音數據庫,就能獲得一個穩健的統計模型,提高在各種實際情況下的識別效率。
1 Markov鏈及隱馬爾可夫模型(HMM)
語音信號是一個可觀察的序列,在足夠小時間段上特性近似于穩定,但其總的過程可看作依次從相對穩定的某一特性過渡到另一特性,在整個分析區間內可將許多線性模型串接起來,這就是Markov鏈。Markov鏈是Markov隨機過程的特殊情況,即Markov鏈式狀態和時間參數都離散的Markov過程。
隱馬爾可夫模型是對語音信號的時間序列結構建立統計模型,可將之看作一個數學上的雙重隨機過程:一個是用具有有限狀態數的Mar-kov鏈來模擬語音信號統計特性變化的隱含的隨機過程,另一個是與Mark-ov鏈的每一個狀態相關聯的觀測序列的隨機過程。前者通過后者表現出來,但前者的具體參數是不可測的。
一般來說,一個HMM是一個雙重隨機過程,由下述五個參數描述:

2 基于HMM的語音識別系統實現
人的言語過程實際上就是一個雙重隨機過程,語音信號本身是一個可觀測的時變序列,是由大腦根據語法知識和言語需要(不可觀測的狀態)發出音素的參數流。HMM合理地模仿了這一過程,很好地描述了語音信號的整體非平穩性和局部平穩性,是較為理想的一種語音模型。從整段語音來看,人類語音是一個非平穩的隨機過程,但是若把整段語音分割成若干短時語音信號,則可認為這些短時語音信號是平穩過程,就可以用線性手段對這些短時語音信號進行分析。若對這些語音信號建立隱馬爾可夫模型,則可以辯識具有不同參數的短時平穩信號段,并可以跟蹤它們之間的轉化,從而解決了對語音的發音速率及聲學變化建立模型的問題。
語音識別系統首先通過芯片內的A/D轉換器將模擬語音信號轉化為數字語音信號,然后對數字語音信號進行處理(信號加窗、過濾),得到干凈的語音信號,再通過特征提取過程做出特征矢量,提取語音特征,最后由識別過程對說話人語音進行識別,得出識別結果。總體來說,整個識別過程分為語音信號的預處理、語音信號的特征提取、語音庫的建立以及語音信號的識別等幾個主要階段,如圖1所示。
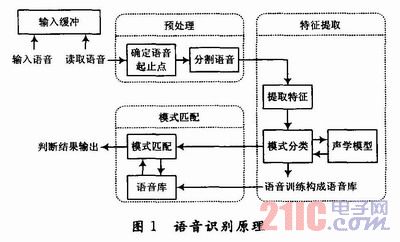
語音識別過程分為兩個部分:一是HMM訓練過程,得到HMM語音識別模型,即建立基本識別語音庫;二是HMM識別過程,得到語音識別結果。
2.1 HMM訓練
HMM算法是解決識別問題的一種常用方法。一個HMM模型中有N個狀態,對于一個長度為T的觀察序列,如果按照定義來計算,需要2TNT次運算,這種運算量是不能接受的,而HMM算法可以簡化這個過程。



如果P(O/λZ)和![]() 距離太大,則返回步驟(2),反復迭代運算,直到HMM模型參數不再發生明顯的變化為止。
距離太大,則返回步驟(2),反復迭代運算,直到HMM模型參數不再發生明顯的變化為止。
2.2 HMM模型識別
HMM模型的輸出概率用Viterbi算法計算,因為概率值一般都遠小于1,這里用取對數后的概率作為輸出值:
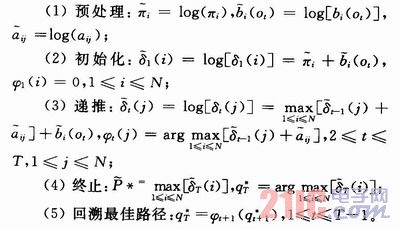
以上式中δt(i)表示t時刻第i個狀態的累積輸出概率;φt(i)表示t時刻第i個狀態的前續狀態號;![]() 為最優狀態序列中t時刻所處的狀態;P*為最終的輸出概率。
為最優狀態序列中t時刻所處的狀態;P*為最終的輸出概率。
3 實驗結果
系統首先通過語音錄入模塊的麥克風將語音信號輸入UDA1341 TS數字音頻處理芯片,通過S3C2410向UDA1341數字音頻處理芯片發送指令,數字音頻處理芯片由內部A/D對語音信號進行采樣,調用語音壓縮算法對語音信號進行壓縮,并調用語音識別函數API對輸入語音進行基于模式匹配算法的語音識別,最終UDA1341數字音頻處理芯片將識別結果通過I/O傳送到ARM S3C2410,S3C2410接收到識別結果后,根據不同的識別結果再向UDA1341 TS發送不同指令,以此實現語音識別系統的功能。
系統采用三星的S3C2410作為嵌入式CPU,這是一款高性價比、低功耗、高性能、高集成度的CPU,基于ARM9核,主頻為203 MHz,專為網絡通信和手持設備而設計,能滿足語音識別系統中的低成本、低功耗、高性能、小體積的要求。
實驗采用10字中文數碼,分別在室外環境和實驗室環境下測試,結果如表1所示。

通過測試表明,在實驗室環境下該系統在UDA1314TS DSP芯片上得到的結果比較令人滿意,具有良好的魯棒性,識別率達到實用要求,但在室外較高噪音條件下的識別率相對實驗室環境下有一定差距,滿足語音識別基本要求。
4 結論
本文系統采用隱馬爾可夫模型的語音識別算法,能夠對小詞量、連續語音進行識別,識別率較高。ARM S3C2410微處理器和UDA1314TS音頻處理芯片的結合應用,能使本語音識別系統具有較強的實時性。體積小,攜帶方便,使用靈活,可移植性強的特點使系統在進一步改進和發展后能夠用于工業語音控制領域中,還可用于聲控玩具、聲控設備等人們的日常生活中。
但由于技術水平和硬件環境的限制,該語音識別系統在算法、硬件方面都需要進一步的研究和完善。該嵌入式語音識別系統的研究為進一步開發和研究實用性嵌入式語音識別系統做出了重要的嘗試和探索工作。