
??? 摘 要:針對OSEK標準的應用設計了一個從OIL代碼到C代碼的自動生成系統,該系統允許用戶輸入OIL配置文件信息,讀取用戶的輸入轉換為標準的C程序,返回給用戶,在具體應用的時候,文法限制嚴格。該系統結合代碼自動生成的過程,提出了一些具體的解決過程,消弱了對文法輸入的限制,提高了對文法的適應能力。
??? 關鍵詞: 代碼自動生成;OIL;LL(K)
?
??? 代碼自動生成是當今自動化程序設計的一個熱點,代碼自動生成技術就是幫助程序員完成系統底層的、重復性代碼的自動生成,減少軟件開發中枯燥且重復的編碼工作,使得程序員將更多的時間花在系統架構研究、軟件工程學習等方面,從而提高軟件系統健壯性、可擴展性以及可維護性和生產率,縮短項目開發時間,節約項目的開發成本,降低項目開發風險,提高軟件公司的信譽度,贏得市場主導地位,使公司獲得最大回報率。OIL配置文件是對OSEK標準的描述文件,OSEK/VDX是應用在模塊和靜態實時操作系統上的標準,由主要的汽車制造商和供應商、研究機構以及軟件開發商發起。在具體的開發過程中,往往要根據OIL文件的描述來進行具體的編碼,將代碼自動生成技術應用于OIL文件上,可以減少程序員的大量手工開發,節省了大量的人力物力,具有相當廣泛的工業應用前景。本文設計的系統接受用戶輸入的OIL配置文件,然后經過系統的分析生成相應的C代碼,實現了從配置文件到具體程序的自動化,節省了大量的人力物力,并且在嵌入式開發的時候可以繼承到嵌入式開發環境中,提供了很大的便捷性。
1 OIL代碼自動生成系統的設計與實現
1.1 OIL代碼自動生成系統的功能描述
??? 本文中代碼自動生成系統的設計模塊如圖1所示。
?

??? OIL代碼自動生成系統的輸入模塊主要是提供兩種方式讓用戶輸入OIL配置文件:一是用戶輸入完OIL配置文件后提供保存功能,此時將用戶輸入的配置文件保存到用戶制定的文件夾內;二是提供選擇功能,讓用戶選擇已經保存好的配置文件或者是使用其他工具生成的配置文件,將文件讀取進系統。
??? 當用戶確定輸入的配置文件并點擊生成按鈕后,此時由分析模塊對用戶輸入的配置文件進行分析,系統根據系統規定好的產生式規則進行判定,首先對配置文件進行分詞,系統根據輸入好的正則表達式提供有窮自動機的功能,對用戶的配置文件進行詞法分析,將用戶輸入的字符串分割成符合OIL規范的字符集作為下一步語法分析的輸入,此時得到的文件應該是具有標記的字符串集合。隨后的語法分析模塊對詞法分析得到的結果進行分析,根據預先設定的正則表達式來判定句子是否符合語法規則,采用LL(K)進行產生式匹配,并且在匹配后建立相對應的語法樹,為后面的C代碼生成打基礎。此后再進行語義分析,通過對語法樹進行分析,得到帶有注釋的語法樹,方便后面的轉換模塊進行遍歷。
??? 轉換模塊的工作主要是收集要生成的C程序中必要的數據,例如CPU的信息、消息間的相互聯系、以及中斷和警告的信息等,通過對這些必要信息的記錄來實現從配置文件到C程序的數據的映射,通過對前面OIL語法樹的遍歷得到這些數據。
??? 結果輸出模塊是主要是進行模板構造,對轉換模塊中得到的需要的數據和設定的模板相結合,然后輸出,得到最后要生成的C程序。
1.2 OIL代碼自動生成系統的核心工作流程
??? OIL代碼自動生成系統的工作流程如圖2所示,圖2描述出了整個系統的核心工作流程:從用戶輸入代碼到輸入模塊,一直到輸出C代碼返回給用戶。
?
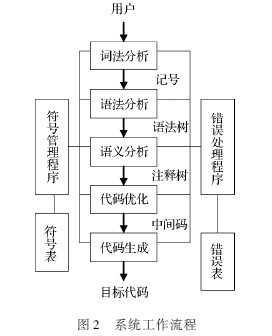
??? (1) 詞法掃描。詞法掃描程序對源程序進行掃描,從中收集到有意義的字符序列,收集到記號中。
??? (2) 語法分析。程序依據文法規則,從掃描程序中獲取記號形式的源代碼,完成程序結構的語法分析,從而確定整個輸入串是否構成一個語法上正確的程序,并輸出語法樹。
??? (3) 語義分析。審查源程序有無語義錯誤,并為代碼生成收集必要的信息。
??? (4) 代碼優化程序。對于語義分析形成的注釋樹進行遍歷,取得需要的數據。
??? (5) 代碼生成部分。根據前面取得的信息將信息以符合C程序的形式組織起來形成C代碼。
2 OIL代碼自動生成系統中關鍵技術的研究
??? 本系統采用的是自上而下的LL(K)分析方法,所以本系統可以接受的文法必須是一個正確的、上下文無關文法,該文法不僅能夠正確完整地反映出OIL的語法,并且應該符合自頂向下分析的要求,這個就要求該系統能夠處理以下幾種情況:
??? (1) 如何處理出現二義性;
??? (2) 克服左遞歸弊端;
??? (3) 如何確定LL(K)中K的值以保證正確識別文法和效率之間的統一。
??? 文法的二義性是指對于同一句子有兩種不同的語法樹,則稱該句子是二義性的,稱產生該句子的文法為二義性文法。解決二義性的方法有兩種:一種是設置一種規則,該規則指出在二義性的情況下哪種語法樹是正確的,例如在ELSE問題上面,規定每個ELSE和最近的沒有分配的IF匹配,這種方法的優點是無需修改文法就可以克服文法的二義性,缺點是此時語言的語法結構就不能由文法單獨決定了;另外一種方法就是對存在二義性的文法進行改寫,如果一個二義產生式右部有非終結符出現一次以上,可以利用產生式引入消除,如產生式A→a BβBγ,可以變換為A→a BβA′,A′→Bγ.如果多候選產生式的右部有一個是二義性的,那么每個右部都要作為這個代換部分移除,例如A→aAβAγ|a1|a2|…|an,轉換為A→aA′βAγ| A′, A′→A′|a1|a2|…|an,消去其中的無用產生式后得到,A→aA′βAγ| A′, A′→a1|a2|…|an。如果一個產生式有多個二義性產生式,可以用上述方法重復變換。
左遞歸是指當一個上下文無關文法G=(VN ,VT , P, S),其中VN、VT、P、S分別表示非終結符集、終結符集、產生式和開始字符,當文法如下:(1)A→Aa|β,其中A∈VN, a, b∈V*,此時認為這是直接左遞歸,(2)A→Ba,B→Aβ|γ,其中A∈VN , α, β, γ∈V*,此時稱為間接左遞歸,當出現左遞歸的時候,由于本文采用的是LL(K)文法是采用從左到右的掃描方法,當掃描到(1)中的A或者(2)中的B時,此時無法確定LL(K)掃描中的FIRST集,會導致掃描失敗。對于兩步以上的左遞歸(2)可以轉換為直接左遞歸形式A→Aβa |γa,然后利用下面的算法消除。此算法可以消除所有無循環推導和空產生式的文法中的左遞歸:
(1) 以某種順序排列非終結符A1,A2,...AN。
(2) For i = 1 to n do begin
????? For j = 1 to i-1 do begin
??????????????????? 用產生式Ai→δ1γ/δ2γ/…/δkγ代替每個形如Ai→Ajγ的產生式,其中Aj→δ1/δ2/…/δk是當前Aj的所有產生式
????? End
??? 消除Aj產生式中的直接左遞歸
??? End
??? 在使用LL(K)算法的時候,如何確定步長是一個很關鍵的問題,如果步長過大,那么每次掃描的時候向前看的單詞數過多,會引起編譯效率的下降;如果步長過小,當兩個非終結符具有相同的FIRST(K)值會導致識別的失敗。一般來說,選取K值為1的時候能滿足通常的識別要求,但是在某些特定的情況下可能導致識別失敗,不能保證系統的健壯性,例如在以下的情況下使用LL(1)就不能滿足要求:
??? (1) 當出現A→αβ1|αβ2|…|αβn的時候,此時如果要對產生式進行展開的話,采用LL(1)無法確定展開后應該采用那個產生式。
??? (2) 當出現左遞歸的時候或者步長為K的時候才能區別的產生式。
??? (3) 當根據以下規則進行詞法分析:
??? Float:(DIGIT)+’.’+(DIGIT)*+; 浮點型
??? ARRAY: (DIGIT)+’..’+(DIGIT)+;數組
??? 當在這種情況下,由于兩個產生式都無法確定前面的DIGIT的個數,只有當掃描到“.”或者“..”的時候才能確定該使用哪個產生式,因此此時無法使用LL(1)進行確定。
??? 當出現(1)的情況時,此時采取提取公因子的方式對產生式進行改寫,例如(1)中的產生式可以改寫為如下格式A→αA',A'→β1|β2|…|βn的形式進行轉化,此時采用LL(1)可以成功進行掃描,如果公因子比較長的話可以采取上述辦法進行多重轉化。
??? 對于左遞歸的情況上述已經提到過解決方法了,對于步長為K才能區別的情況下,此時可以將步長調整到K進行掃描,但是使用固定K值采用LL(K)的方法進行掃描的時候,會要求對終結符的FIRST集進行計算,這樣對許多無需使用LL(K)的情況造成了資源的浪費,使得掃描的效率降低。
??? 當出現情況(3)的時候無論將K值定為多長都有可能出現K值不夠大而形成掃描失敗的情況,此時應該采取步長不確定的方式來進行掃描:當剛剛開始掃描的時候確定K的初始值為1,當掃描失敗的時候,如果確定失敗的原因是由以上第三種情況導致的話,此時對K的值加1進行掃描,如果失敗再次加1直到掃描成功。根據對OIL的語法進行觀察,當K值定為3的時候就能解決99%以上的掃描失敗問題。對于少數為4的情況下可以采取提取公因子的情況進行轉化。
??? 采用遞歸下降分析程序掃描失敗后會返回失敗的節點,這種返回原節點的方式稱為回溯,在編譯過程中這樣的現象被認為是一種極大降低效率的現象,因此要盡力避免回溯的出現。為了避免回溯的出現,在每次選擇產生式的時候采取預測分析的方法,即禁止回溯,當需要確定使用產生式的時候采取預測的方法,使用預測的產生式,如果失敗則報錯,這樣就避免了回溯的出現。預測是使用預測函數來實現的,預測函數就是確定下一個待輸入的字符是否在當前產生式A的預測函數中predict(A)中,如果在的話,就選擇產生式A,預測函數就是產生式A的向前看K個單詞,下列產生式A→X1X2X3…XN,如果向前看的單詞K個數為1的話,則此產生式的預測函數的定義為如下:
??? 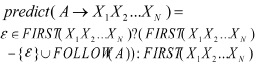
??? 如果兩個右部產生式的預測函數有非空交集的時候,還需要往前看K個字符,以上的方法一般表現為一個分析表,表的行表示非終結符,表的列表示終結符,表和列的交叉點就是當非終結符遇到該終結符該使用哪個產生式去進行擴展。
??? 本文探討了代碼自動生成技術的一些步驟,并提供了OIL代碼自動生成技術的系統模型。文中提出了一些在OIL代碼自動生成詞法分析和語法分析過程中遇到的實際問題加以討論并提出了實際的解決辦法,為下一步語義注入提供了基礎。本系統的實際開發遵循了MVC開發方式,保證了先進性,并且為代碼自動生成技術提供了一些可以參考的思路。
參考文獻
[1]?LOUNDER K C. 編譯原理及實踐[M]. 馮博琴, 馮嵐,譯. 北京:機械工業出版社, 2000.
[2]?陳火旺, 劉春林. 程序設計語言編譯原理(第3 版)[M]. 北京:國防工業出版社, 2001.
[3]?呂映芝, 張素琴. 編譯原理[M]. 北京:清華大學出版社, 1998.
[4]?APPEL A W, PALSBERG? J. Modern compiler implementation in java[M]. 高等教育出版社, 2003.
[5]?APPEL A W. 現代編譯原理C 語言描述[M] . 趙克佳, 黃春, 沈志宇,譯. 北京:人民郵電出版社出版,2006.