
摘 要: 研究了一種基于OpenMP技術的多核架構下并行蟻群算法,通過在TSP問題中的實驗表明,該算法易于操作,而且充分利用了多核處理器并行計算的優勢,提高了算法的運行效率。
關鍵詞: 蟻群算法; 多核并行計算; OpenMP
蟻群算法是由意大利學者DORIGO M提出的,主要應用于求解組合優化問題,該算法首先應用在旅行商(TSP)問題并取得較好的效果。蟻群算法不僅能夠智能搜索、全局優化,而且具有穩健性、正反饋、分布式計算、易與其他算法結合等特點。然而該算法基本上都是基于單CPU串行執行的, 在求解問題規模較大時, 存在收斂速度較慢等缺點。
隨著多核處理器的普及,如何讓傳統的單CPU串行程序充分發揮高性能多核處理器的功效,是一個現實而嚴峻的問題。解決這一難題的有效途徑之一就是并行計算。為了將計算能力最大化,需要將算法代碼中的計算任務劃分為多個部分,并交由多個處理器核心同時處理。要實現這一目標,需要一種全新的程序設計模型,目前比較流行的并行程序設計模型之一就是用于共享內存編程的OpenMP。本文將對基于OpenMP的多核架構下并行蟻群算法的實現進行介紹,并通過對大規模TSP問題進行實驗驗證OpenMP多核并行計算技術能夠大大提高蟻群算法的運行效率。
1 OpenMP簡介
OpenMP是一種面向共享內存以及分布式共享內存的多處理器多線程并行編程語言,具有良好的可移植性,同時支持Fortran、C和C++。OpenMP程序設計模型提供了一組與平臺無關的編譯指導、指導命令、函數調用和環境變量,可以顯式地指導編譯器利用應用程序中的并行性。它能夠為編寫多線程應用程序提供一種簡單的方法,通過編譯指導語句,可以將串行的程序逐步地改造成一個并行程序,從而減少程序編寫人員的負擔。
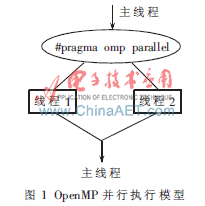
OpenMP程序開始于一個單獨的主線程。主線程會一直串行地執行,直到遇見第一個并行域才開始并行執行。并行域表示該部分程序計算量大,需要多個處理器共同處理以提高效率和運行速度。并行域以外的部分表示該部分的程序不適宜或者不能并行執行,只能由一個處理器來執行。主線程創建一組并行線程,然后并行域中的代碼在不同的線程中并行執行,當主線程在并行域中執行完后,它們可能被同步或被中斷,最后只有主線程在執行。OpenMP的并行執行過程如圖1所示。例如對于for循環語句for(int i=0; i<100; i++),按常規串行處理時,i要按順序執行從0~99。如果在雙核環境下,則分成兩個線程,兩個CPU執行核同時處理,核0執行i從0~49,核1執行i從50~99,理論上可以節省一半的時間。而這種從串行執行到并行執行的改變,只需要一條OpenMP編譯指導指令就可以完成。編譯指導語句的含義是在編譯器編譯程序時,會識別特定的注釋,而這些特定的注釋就包含著OpenMP程序的一些語義。例如在C/C++程序中,用#pragma omp parallel來標識一段并行程序塊。在一個無法識別OpenMP語義的普通編譯器中,會將這些特定的注釋當作是普通的注釋而被忽略。因此,如果僅僅使用編譯指導語句,編寫完成的OpenMP程序就能夠同時被普通編譯器與支持OpenMP的編譯器處理。這種性質帶來的好處就是可以用同一份代碼來編寫串行或者并行程序,或者在把串行程序改編成并行程序時,保持串行源代碼部分不變,大量的工作都由編譯器自動執行,從而極大地方便了程序編寫人員。
2 蟻群算法
2.1 基本原理
根據仿生學家長期的研究發現: 螞蟻雖然沒有視覺, 但運動時會在路徑上釋放出一種名為信息素的特殊分泌物來尋找路徑。螞蟻走的路徑越長, 則釋放的信息素數量越小。當后來的螞蟻再次碰到這個路口的時候, 選擇信息素數量較大路徑的概率就會相對較大, 這樣形成了一個正反饋機制。螞蟻之間交換著路徑信息, 最終通過蟻群的集體自催化行為找出最優路徑。
2.2 蟻群算法的數學模型
為了能夠清楚地表達蟻群算法的數學模型, 本文借助了經典的TSP問題。給定n個城市的集合{1,2,3,…,n-1}及城市之間環游的花費Cij(0≤i≤n-1,0≤j≤n-1,i≠j)。TSP問題是指找到一條經過每個城市一次且回到起點的最小花費的環路。若將每個頂點看成是圖上的節點,花費Cij為連接頂點Vi和Vj邊上的權,則TSP問題就是在一個具有n個節點的完全圖上找到一條花費最小的漢密爾頓路。
設在TSP問題中有n個城市和m個螞蟻,把m個螞蟻隨機放在n個城市中(m≤n)。每個螞蟻的行為符合下列規律:根據路徑上的信息素濃度,以相應的概率來選取下一步路徑;不再選取自己本次循環已經走過的路徑為下一步路徑。用禁忌表tabuk(k=1,2,…,m)來記錄螞蟻k當前所走過的城市,集合tabuk隨著進化過程作動態調整;當完成了一次循環后,根據整個路徑長度來釋放相應濃度的信息素,并更新走過的路徑上的信息素濃度。

3 基于OpenMP的并行蟻群算法實現
蟻群算法本身具有很高的并行性,所有螞蟻能夠獨立構建問題的可行解,每個螞蟻在構建解的過程中只與當前的信息素和啟發函數有關,只有在所有螞蟻均完成了可行解的構造之后,信息素更新時存在螞蟻間的通信。因此可以將各個螞蟻構建可行解的過程分配到不同的線程中并行執行。
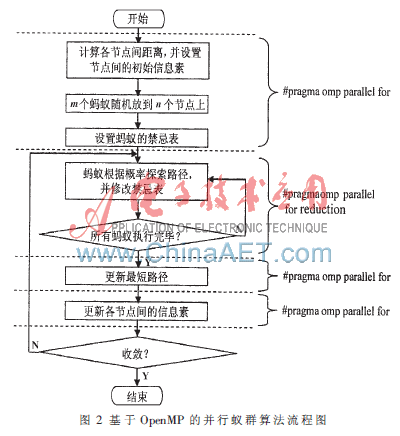
在蟻群算法中,運算量主要集中在每一只螞蟻重新計算建立回路以及每次循環結束前更新路徑上的信息素,即串行蟻群算法的大部分計算集中在for循環部分,同時也是算法復雜度的主要來源。當節點數目很大時,可以將計算循環分割成若干個部分,每個部分就可以在一個獨立的硬件線程上完成。本文給出基于OpenMP的并行算法設計,目的是在不改變算法行為的前提下提高算法的執行效率,充分利用多核處理器的優勢。基于OpenMP的并行蟻群算法的主要過程為:
(1)初始化過程:通過OpenMP中的編譯指令#pragma omp parallel for對算法進行初始化。初始化工作主要包括計算任意兩個節點間的距離、計算τij的初始值、把m個螞蟻隨機放到n個城市上和設置螞蟻的禁忌表tabuk。通過OpenMP中的#pragma omp parallel for對初始化操作進行并行處理,把初始化工作中大量的循環迭代和循環賦值任務分配到不同的處理器核上并行執行。
(2)螞蟻探索路徑過程:螞蟻根據概率Pijk選擇下一個節點j,將第k個螞蟻移到節點j,并將j插入到禁忌表tabuk中。在求Pijk時可以通過OpenMP中的reduction語句使循環迭代中的累加操作并行執行。reduction語句可以為每一個線程創建累加變量的私有同名變量,并行代碼執行結束后,每一個私有同名變量會按加法操作依次進行規約,更新主線程中的原始變量的值。
(3)更新最短路徑。當所有螞蟻遍歷完所有節點后,通過OpenMP中的編譯指令#pragma omp parallel for并行計算每個螞蟻走過的總路徑長度Lk,并更新找到的最短路徑。
(4)更新信息素。計算螞蟻產生的信息增量,更新路徑上的信息素。節點間的信息素是殘留的信息素和信息素增量的疊加。殘留信息素的循環計算是獨立的,可以通過#pragma omp parallel for進行并行處理。而信息素增量的計算需要各個螞蟻之間的通信,為了避免并行過程中頻繁的通信,不使用OpenMP并行優化,而采用串行計算。
(5)運行結束。若循環次數沒有達到預定次數,則重復執行第(2)步,否則運行結束,打印最佳路徑。
算法的執行過程如圖2所示。
4 實驗結果及分析
本文所設計的算法在Intel酷睿2雙核E7500處理器上進行實驗,串行蟻群算法和基于OpenMP的并行蟻群算法的實驗比較結果如表1所示。實驗結果表明:當問題規模比較小時,串行蟻群算法和基于OpenMP的并行蟻群算法的運行時間相差不大,但隨著問題規模的擴大,并行算法的運行時間將會縮短到原來的50%左右,明顯提高了算法的運行效率。

串行蟻群算法和基于OpenMP的并行蟻群算法在解決同樣規模問題時,CPU 的使用情況如圖3和圖4所示。結果表明:串行算法不能充分利用兩個處理核心的資源, CPU的使用率在50%左右,造成了資源的浪費,而OpenMP設計的并行算法充分利用了兩個處理核心資源,使CPU的使用率達到100%,這也正是蟻群算法運行效率提高的原因。

本文研究了一種基于OpenMP的多核架構下并行蟻群算法,并在TSP問題中對算法進行了驗證。并行優化計算過程簡單靈活,易于操作,而且充分利用了多核處理器的優勢,提高了算法的運行時間效率,為解決大規模組合優化問題提供了可能。
參考文獻
[1] 夏鴻斌,須文波,劉淵. 基于多蟻群的并行 ACO 算法[J].計算機工程,2009,35(22): 23-28.
[2] 黃亞平,王萬良,熊婧.基于自適應蟻群算法的作業車間模糊調度研究[J].計算機仿真, 2009, 26(4):244-248.
[3] 何麗莉,王克淼,白洪濤,等.基于CMP 的多種并行蟻群算法及比較[J]. 吉林大學學報(理學版),2010,48(5):787-792.
[4] 多核系列教材編寫組.多核程序設計[M].北京:清華大學出版社, 2007.
[5] 姜長元. 蟻群算法的理論及其應用[J]. 計算機時代,2004(6):1-3.
[6] 閻芳,楊璽,陳蕾.基于OpenMP的并行蟻群物流調度算法研究[J]. 物流技術,2010(13):91-93.
[7] 李妮,高棟棟,龔光紅.基于TBB 多核平臺的并行蟻群算法實現[OL-EB]. http://www.paper.edu.cn.