
摘 要: 現今,OCR文字識別技術已經飛快發展,如一般的車牌識別、掃描文本識別等技術的識別率已達到非常高的水平,但這些識別技術在帶水印圖片的文字識別這一方面表現一般。其原因主要在識別前后的處理還不夠。主要講述了文字識別的新預處理的方法和后期處理的實現。
??? 關鍵詞: USM銳化;最大類間方差;閾值;平均灰度值;二值化閾值;拼寫與語法檢查
?
所謂帶水印的圖片,其實就是在文字的上面加上一層半透明的圖像,如圖1所示。這層圖像不會影響讀者對文字的閱讀,但如果計算機要提取圖片里面的內容就會非常的困難。
?

為了能準確且方便地從帶水印的圖片中提取內容,本文對圖片的預處理分成三步:第一步是進行灰度處理,第二步是用自動獲取閾值的USM銳化,最后是對圖片進行二值化處理。
在眾多文字識別技術中,暫時還沒有一種識別方法能保證識別出來的內容是準確的,因此,在進行識別后的檢查和糾正就顯得很重要。為了在識別錯誤后能盡量地糾正,需要對識別結果進行拼寫和語法檢查及糾正。所以在本文的后部分還介紹一種簡單的識別結果糾正程序。
1 文字識別的預處理
1.1 灰度處理
灰度處理主要是對圖片中每一像素的RGB值進行映射,映射到0至255的灰度值。所以得出來的圖片就像黑白照片一樣。這樣做就可以降低后面步驟的運算量,并且使得圖片更加易于辨認。效果圖如圖2所示。

1.2 USM銳化
由于水印是半透明地蓋在文字資料上,使得水印下的文字的邊緣變得模糊且難以辨認,因此要對圖片銳化,這樣會突顯圖片中的文字,有利于實現圖片中的文字與水印分離。
? 在這里不用一般的銳化方法,因為一般的銳化方法只是對邊緣進行增強,而USM銳化則不一樣。USM銳化前和USM銳化后的圖分別為圖3和圖4。

? 從圖3和圖4的對比中,可以清楚地看到,USM銳化不單可以把文字一邊的邊緣增強,同時它還把文字邊緣的另外一邊明顯地減弱。通過這種方法,文字就會被突顯出來,而文字附近的圖像就會被減弱,從而減少半透明水印的面積。并且文字的邊緣還會出現白邊(其實是由于邊緣減弱造成的部份),這就為下一步二值化埋下了伏筆。
USM銳化算法中的閾值是需要設定的,閾值過大,銳化就不能產生出效果;設定的閾值過小,那么就會同時把文字與水印的邊緣都增強,什么都分不清楚了。由于閾值的設定至關重要,閾值是通過最大類間方差法定下來的,方法如下:
對于圖像I(x,y),前景(即目標)和背景的分割閾值記作T,屬于前景的像素點數占整幅圖像的比例記為w0,其平均灰度u0;背景像素點數占整幅圖像的比例為w1,其平均灰度為u1。圖像的總平均灰度記為u,類間方差記為g。
假設圖像的大小為M×N,圖像中像素的灰度值小于閾值T的像素個數記作N0,像素灰度大于閾值T的像素個數記作N1,則有: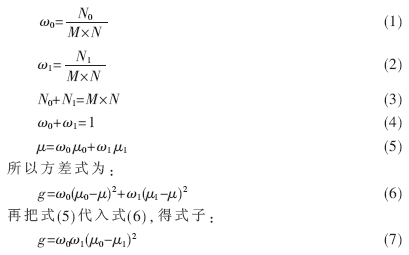
然后,在程序中使T值遍歷0到255,每次都算出方差值g,最后能使g最大的T值就是需要的閾值。但T值無需遍歷那么多次,因為文字一般都接近黑色,所以可以遍歷從1到90。灰度圖片USM銳化后的效果如圖5所示。

1.3 二值化處理
??? 通過二值化處理就可以得到主要的文字的圖片了。而這一步最重要的地方是二值化處理時要選取的閾值,閾值決定了能否把圖片中的水印圖除掉。通過以下方法算出閾值:
??? (1)橫向掃描全圖,把兩邊為淺色、中間為深色的所有點(如圖6中F被橫框選中處)的灰度值累加(設總值為sum1),同時也累記點數(設總數為p1)。
??? (2)縱向掃描全圖,把上下兩邊為淺色、中間為深色的所有點(如圖6中F被縱框選中處)的灰度值累加(設總值為sum2),同時也累記點數(設總數為p2)。

??? (3)得出的二值化的閾值就為:(sum1+sum2)/(p1+p2)。
??? 簡單來說,就是把被白邊圍上的黑點的灰度值進行累加,它的和與黑點的數量相除,就得到了這些黑點的平均灰度值。這也正是在第二步用USM銳化的原因。用該閾值對圖片進行二值化后的效果如圖7所示。

2 文字識別的后期處理
經過預處理后,就可以用很多現有的OCR文字識別算法把圖7中的文字提取出來,這里就不再進行闡述了。
??? 不難發現,無論預處理做得有多好,識別算法技術有多高,都難免有出錯的時候,因此要對識別的結果進行拼寫和語法的檢查和糾正,這里直接給出實現該功能的程序。眾所周知,微軟office中的word里有拼寫和語法的檢查糾正功能,并且比較完善。
??? 使用VB.NET實現拼寫和語法檢查糾正功能的過程如下:
??? (1)確定已安裝office 2003。VB中已建立windows窗體,窗體中有TextBox,它是存放OCR識別的結果,還有Button,Button中的事件就是拼寫與語法檢查與糾正代碼。
??? (2)在VB中引用Word組件:在解決方案瀏覽器中的“引用”上右鍵->添加引用->標簽頁中選“COM”->選中“Microsoft Word 9.0 Object Library”,單擊“確定”即可。
??? (3)在代碼的最前端添加三個語句:Imports Microsoft.Office.Core,Imports Microsoft.Office.Interop.Word和Imports System. Runtime. Interop Services,然后在Button的單擊事件中加如下代碼即可。
??? Dim objWord,objTempDoc As Object
′創建Word對象和臨時文檔
?? Dim iData As IDataObject
′聲明IDataObject存放從剪貼板返回的內容
??? objWord=New Word.Application
??? objTempDoc=objWord.Documents.Add
′實例化Word對象
??? Clipboard.SetDataObject(TextBox1.Text)
′復制文本框中的識別結果到剪貼板
??? With objTempDoc
??? .Content.Paste()? ′把剪貼板中的內容粘貼到臨時文檔
??? .Activate()
??? .CheckSpelling() ′拼寫檢查
??? .CheckGrammar()? ′語法檢查
??? .Content.Copy()
??? iData=Clipboard.GetDataObject()
??? TextBox1.Text=CType(iData.GetData(DataFormats.Text), String) ′利用剪貼板把修改后的內容返回給文本框
??? .Close()
??? End With
??? objWord.Quit()
??? 本文中所講述的最大類間方差定USM銳化閾值法、基于USM銳化后求黑點平均灰度值的圖像二值化處理法和對識別結果進行檢查糾正,經過多次實驗,針對帶水印圖片的文字識別率可高達98.64%。而前面兩種處理圖像的方法及它們的巧妙結合正是本文的亮點,并且是原創的。但本算法的運行速度并不理想,在以后的研究中希望有新的突破。
參考文獻
[1] 楊柳,牛秦洲.啤酒瓶凸性模號圖像預處理算法[J].電腦知識與技術,2007(11):1089-1091.
[2] 王勇智.數字圖象的二值化處理技術探究[J].湖南理工學院學報(自然科學版),2005(1).
[3] 呂學強,遲呈英.英文光學字符識別的后處理[J].鞍山鋼鐵學院學報,2002(25):192-196.