
文獻標識碼: A
文章編號: 0258-7998(2011)10-0123-03
超高、超長、大跨度的復雜建筑工程設計涉及大量的復雜計算,對高性能計算技術有著重大的需求。目前,傳統的建筑工程設計的高性能有限元分析軟件工具主要基于并行計算技術。高性能并行計算以MPI標準為代表[1],其中最為著名且被廣泛使用的是由美國Argonne 國家實驗室完成的MPICH,它廣泛應用于各種建筑結構計算軟件(如ANSYS、FLUENT、PATRAN)中。然而,MPI進行數據處理主要方式是將作業分配給集群,由集群訪問以存儲區域網絡為管理基礎的共享文件系統,在大量數據的情況下網絡帶寬將限制這種處理方式[2],而新出現的云計算技術能夠有效地解決這個問題。云計算是IT界新近提出的以Hadoop技術為代表的分布式計算模式,Hadoop的MapReduce模式具有計算節點本地存儲數據的特性,能夠有效地避免MPI的網絡帶寬限制問題。相對于MPI賦予程序員的可控性,MapReduce則是在更高的層面上完成任務。
本文闡述了建筑結構并行計算(MPI)的云計算的應用方法和思想,利用Google的MR_MIP庫(Library)結合相應程序接口,發揮兩種計算方法各自的優勢,實現了云計算與MPI相互融合。既利用了傳統的基于并行計算技術的建筑計算軟件的豐富資源,又使用云計算技術解決了現有方法存在的問題。
1 云計算與Hadoop
云計算(Cloud Computing)是網格計算、分布式處理和并行處理的發展[3],是計算機科學概念的商業實現。其基本原理是把計算分配到大量的分布式計算機,而不是分配到本地計算機或遠程的服務器上,使企業數據中心的運行類似于互聯網。企業能夠將有限的資源轉移到需要的應用上,并根據自身需求訪問計算機及存儲系統,降低了企業的成本。
云計算是一種革命性的舉措,即把力量聯合起來給其中的某一個成員使用,計算機的計算能力能像商品一樣費用低廉取用方便。云計算最大的特點是通過互聯網提供服務,只需要一臺筆記本或者一個網絡終端,而不需要用戶端安裝任何應用程序實現需要的一切,甚至包括超級計算等服務。
IBM于2007年底推出了“藍云(Blue Cloud)”計劃,同時推出許多云計算產品。通過構建一個類似分布式的資源結構,把計算從本地機器和遠程服務器轉移到類似于互聯網的數據中心運行。Hadoop是基于Google Map-Reduce計算模型的開源分布式并行編程框架[4],根據Google GFS設計了自己的HDFS分布式文件系統[5],使Hadoop成為一個分布式的計算平臺。同時還提供了基于Java的MapReduce框架,能夠將分布式應用部署到大型廉價集群上。
Hadoop主要由分布式文件系統HDFS(Hadoop Distributed File System)和MapReduce兩部分構成。HDFS 有著高容錯性的特點,并且設計用來部署在低廉的硬件上。它提供高傳輸率來訪問應用程序的數據,適合那些有著超大數據集的應用程序。MapReduce依賴于HDFS實現,通常MapReduce會在集群中數據的宿主機上進行最便捷的計算。
2 MPI標準
消息傳遞接口MPI(Message Passing Interface)是支持在異構計算機上進行計算任務的并行平臺[6],它是一種編程接口標準,而不是一種具體的編程語言。該標準是由消息傳遞接口論壇MPIF(Message Passing Interface Form)發起討論并進行規范化。該標準的主要目的是提高并行程序的可移植性和使用的方便性。MPI并行計算環境下的應用軟件庫以及軟件工具都可以透明地移植,是目前最重要的并行編程工具。MPI的最大優點是其高性能,具有豐富的點到點通信函數模型、可操作數據類型及更大的群組通信函數庫。
MPI標準定義了一組具有可移植性的編程接口。設計了應用程序并行算法,調用這些接口,鏈接相應平臺上的MPI庫,就可以實現基于消息傳遞的并行計算。正是由于MPI提供了統一的接口,該標準受到各種并行平臺上的廣泛支持,這也使得MPI程序具有良好的移植性。目前MPI支持多種編程語言,包括Fortran 77、Fortran 90以及C/C++;同時,MPI支持多種操作系統,包括大多數的類UNIX系統以及Windows系統等;同時還支持多核、對稱多處理機、集群等各種硬件平臺。
2.1 MPI的通信模式
(1)標準通信模式(StandardMode)。在MPI采用標準通信模式時,是否對發送的數據進行緩存是由MPI自身決定的,而不是由程序來控制。如果MPI決定緩存將要發出的數據,發送操作不管接收操作是否執行都可以進行,而且發送操作可以正確返回而不要求接收操作收到發送的數據。
(2)緩存通信模式(BufferedMode)。緩存通信模式若需要直接對通信緩沖區進行控制,可采用緩存通信模式。在這種模式下由用戶直接對通信緩沖區進行申請、使用和釋放,因此緩存模式下對通信緩沖區的合理與正確使用是由程序設計人員自己保證。采用緩存通信模式時,消息發送能否進行及能否正確返回,不依賴于接收進程,而是完全依賴于是否有足夠的通信緩沖區可用,當緩存發送返回后,并不意味者該緩沖區可以自由使用,只有當緩沖區中的消息發送出去后才可以釋放該緩沖區。
(3)同步通信模式(Synehronous-mode)。同步通信模式的開始不依賴于接收進程相應的接收操作是否己經啟動,但是同步發送卻必須等到相應的接收進程開始后才可以正確返回。因此同步發送返回后意味著發送緩沖區中的數據已經全部被系統緩沖區緩存,并且己經開始發送,這樣當同步發送返回后,發送緩沖區可以被釋放或重新使用。
(4)就緒通信模式(Ready-mode)。在就緒通信模式中,只有當接收進程的接收操作已經啟動時才可以在發送進程啟動發送操作,否則當發送操作啟動而相應的接收還沒有啟動時發送操作將出錯。就緒通信模式的特殊之處在于它要求接收操作先于發送操作而被啟動,因此在一個正確的程序中,一個就緒發送能被一個標準發送替代。該模式對程序的語義沒有影響,而對程序的性能有影響。
2.2 MPI調用的參數說明
對于有參數的MPI調用,MPI首先給出一種獨立于具體語言的說明。對各個參數的性質進行介紹,然后在給出它相對于FORTRAN和C的原型說明。在MPI-2中還給出了C++形式的說明,MPI對參數說明的方式有IN、OUT和INOUT三種。它們的含義分別是: IN為輸入調用部分傳遞給MPI的參數,MPI除了使用該參數外不允許對這一參數做任何修改;OUT為輸出MPI返回給調用部分的結果參數,該參數的初始值對MPI沒有任何意義;INOUT為輸入輸出調用部分,首先將該參數傳遞給MPI,MPI對這一參數引用、修改后,將結果返回給外部調用。該參數的初始值和返回結果都有意義。
如果某一個參數在調用前后沒有改變,例如某個隱含對象的句柄,但是該句柄指向的對象被修改了,則這一參數仍然被說明為OUT或INOUT。MPI的定義在最大范圍內避免了INOUT參數的使用,因為這些使用易于出錯,特別是對標量參數的使用。
還有一種情況是MPI函數的一個參數被一些并行執行的進程用作IN,而被另一些同時執行的進程用作OUT。雖然在語義上它不是同一個調用的輸入和輸出,這樣的參數語法上也記為INOUT。
當一個MPI參數僅對一些并行執行的進程有意義,而對其他的進程沒有意義時,不關心該參數取值的進程可以將任意的值傳遞給該參數。如圖1所示。

3 建筑并行云計算架構
3.1 ANSYS分布式并行計算
ANSYS軟件是最常用的建筑結構有限元求解軟件之一,其核心是一系列面向各個領域應用的高級求解器。ANSYS支持在異種、異構平臺上的網絡浮動,其強大的并行計算功能支持共享內存(share memory)和分布式內存(distributed memory)兩種并行方式。共享內存式并行計算,是指單機多CPU的并行計算、分布內存式并行計算及多機多CPU的并行計算;分布式內存并行往往比共享內存并行有更好的并行效能,ANSYS分布式求解技術核心是基于MPI的編制的計算程序。近幾年,隨著CPU多核,高速互聯等技術的發展,低成本高效率的Linux集群系統成為高性能計算平臺的主流。
3.2 Hadoop的MapReduce 模式計算流程
Hadoop的MapReduce計算架構實現了由Google工程師提出的MapReduce編程模型。它將復雜的、運行于大規模集群上的并行計算過程高度地抽象到了Map和 Reduce兩個函數, 待處理的數據集可以分解成許多小的數據集,而且每一個小數據集都可以完全并行地進行處理。MapReduce的計算流程如圖2所示。
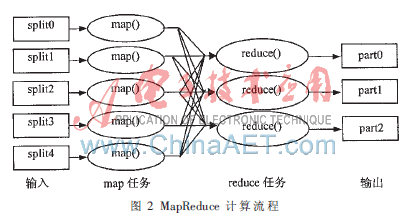
(1)數據劃分。首先將數量眾多的文件進行劃分,分成大小不一的若干小塊數據。通常數據塊大小可以由用戶根據需要自行控制,然后將這些數據塊備份分配到各個機器集群中存儲。
(2)讀取數據并在本地進行歸并。被指定執行映射任務的工作站節點讀取要處理的數據塊,然后從原始數據塊中將數據解析成鍵/值的形式,通過用戶定義的映射函數處理得到中間鍵/值對,存入本地內存緩沖區。緩沖區中的數據集合被劃分函數分配到各個區域,然后寫入本機磁盤。返回管理機本地磁盤中數據的存放位置信息,管理機隨后將這些數據位置信息告訴執行規約任務的相關工作站節點。
(3)指派映射/規約任務。在這些數據塊備份中有一個管理機主程序,其余的均為工作站節點程序,由管理機指派任務給各工作站。主程序將指派處于空閑狀態的工作站來執行規約任務或映射任務。
(4)遠程讀取。在通知執行歸并任務的工作站數據的存儲位置信息后,reduce工作站通過遠程方式讀取執行map任務工作站中的緩存數據。reduce工作站取得所有需要的中間數據后,按照關鍵字對中間數據鍵/值對進行排序,把相同關鍵字的數據劃分到同一類中去。不同的關鍵字映射后都要進行相同的規約操作,所以對中間數據進行排序非常必要。假如產生的中間數據集的數量非常大無法存入內存,可以利用外部存儲器存儲。
(5)寫入輸出文件。最后的reduce工作站對每個歸并操作的中間數據按中間關鍵字進行排列,傳送中間鍵/值對數據給用戶定義的歸約函數。歸約函數的最終輸出結果將被追加到輸出結果文件中。在所有的映射任務和歸約任務完成之后,管理機喚醒用戶程序以繼續之前的程序執行,完成下一階段的任務。
3.3 建筑結構并行云計算方法
建筑結構有限元求解軟件ANSYS支持MPI并行編程模式,如何利用其高效的性能并結合云計算技術是一個新出現的研究問題。使用Google提供的MR_MIP庫(Library)能夠解決這個問題。MR-MPI提供了云計算的MPI庫,結合相應程序接口可以實現并行計算與云計算的結合。圖3給出了兩種先進的計算技術結合的高效能計算過程。

在建筑結構并行云計算的執行過程中,Master占據核心位置,為計算程序的順利運行提供各種服務并負責任務的調度。為將要執行的MPI程序提供MR-MPI庫,同時選擇執行Map和Reduce程序的節點機,讀取節點機上相應的數據塊進行分布式并行計算。同時Master還定期探測worker,當某個testworker任務失敗時,相應的map操作將被通知重起。這種計算模式綜合了云計算和并行計算的各自優勢,在高速計算的同時又實現了系統的負載均衡和故障恢復。
高性能計算技術可高效地解決建筑行業中大型復雜結構高精度分析、優化和控制等問題,從而促進建筑工程結構設計水平和設計質量的提高。本文給出了將Hadoop的MapReduce計算架構與MPI相互整合的應用方法,提出了云計算在建筑結構程序并行化上的應用,為大規模工程計算技術發展提供了新思路。
參考文獻
[1] MATTSON T G. 并行編程模式[M].北京:清華大學出版社,2005.
[2] 王文義,劉輝.并行程序設計環境MPICH的應用機理分析[J].計算機應用,2004,22(4):1-3.
[3] 王鵬. 云計算的關鍵技術與應用實例[M]. 北京:人民郵電出版社, 2010.
[4] WHITE T. Hadoop: the definitive guide[M].Oreilly Media, 2009.
[5] GHEMAWAT S, GOBIOFF H, LEUNG S T. The google file system[J].ACM SIGOPS Operating Systems,2003,9(8):1-5.
[6] 張林波,遲學斌,莫則堯.并行計算導論[M].北京:清華大學出版社,2006.