
摘 要: 采用SoPC方法,實現了基于動態時間規整(DTW)算法的孤立詞語音識別系統,該系統可以作為電器系統的語音命令控制模塊使用。考慮嵌入式系統的特點,對端點檢測算法和模式匹配算法進行了選擇和調整。實驗表明,該語音識別系統運行速度和識別準確性能夠適應語音控制的要求。SoPC設計方式靈活,適合對系統進行改進升級。
關鍵詞: SoPC;Nios II;語音識別;動態時間規整
隨著計算機技術、模式識別技術等的發展,國內外對語音識別的研究也不斷進步。目前電器、家居智能化的實際需求使得語音識別技術成為一個研究熱點。例如,美國約翰·霍普金斯大學語言和語音處理中心多年來一直致力于推動語言和語音識別的研究和教育,CLSP每年一度的夏季研討會對語音識別的各個領域都產生了深遠的影響。國內,中國科學院等也在語音識別領域有較大進展。
相對于基于PC機平臺的大詞匯量語音識別系統,嵌入式系統中要求語音控制模塊占用資源少,功能簡潔,可作為獨立的語音識別系統或其他系統的語音控制部分。因此,根據語音識別系統的準確性、實時性的要求和SoPC實現方式的特點,在介紹實現該語音識別系統的基本流程的基礎上著重探討以下兩部分內容:(1)由于端點檢測算法對識別的準確性影響較大,本系統探索適合SoPC設計的端點檢測算法,從而使得系統的識別準確性有所改進;(2)模式匹配時,對同一模板采用了多個局部判決函數,求多個累加總距離的平均值作為最終的判決依據,進一步提高了識別結果的可靠性。
可編程片上系統SoPC(System on Programmable Chip)是Altera公司提出的一種基于FPGA的嵌入式系統解決方法,采用軟硬件結合設計的思想,實現方式簡單靈活[1]。設計中采用高性價比的EP2C70 FPGA芯片。實驗結果表明,系統運行良好,能夠滿足中、小詞匯量孤立詞語音識別系統的要求。
1 設計方案
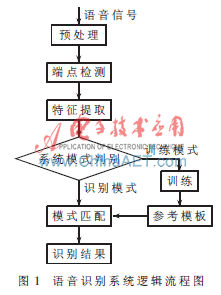
語音識別系統的邏輯流程如圖1所示。采樣得到的語音信號要經過預處理、端點檢測、特征參數提取,然后根據用戶指定的工作模式(識別模式或訓練模式),進行模式匹配并輸出識別結果,或者訓練得到該詞條的模板,并存入模板庫。因此,在硬件資源允許的條件下,用戶可以自定義訓練模板,更新模板庫,拓展系統的應用范圍。
1.1 預加重和端點檢測
系統采用8 kHz采樣,由音頻編/解碼芯片WM8731采樣得到的語音數據,經過FIFO數據緩存器傳輸到系統的SDRAM中,然后對SDRAM中的數據進行后續處理。設定256個采樣點作為一幀,每個孤立詞采集100幀(3.2 s)數據。
(1)預加重:處理的第一步要對采集到的數字語音信號進行預處理,主要是預加重。預加重的目的是提升高頻部分,使信號的頻譜變得平坦,保持在低頻到高頻的整個頻帶中能用相同的信噪比求頻譜。通過一個濾波器對信號進行濾波,濾波器的傳遞函數為:
H(z)=1-0.98z-1(1)
(2)端點檢測:從數字語音信號中快速有效地切分出語音段,對于整個系統的識別速度和識別準確性影響較大。根據漢語語音的特點,一般一個漢語單詞的開始部分是清音,接下來是濁音,清音較弱,濁音較強。因此在端點檢測部分,采用了基于短時能量和短時過零率的雙重檢測。首先根據濁音粗判起始幀,然后根據清音,細判起始幀。語音的起始幀和終止幀都是經過粗判和細判之后得出,從而保證端點檢測的準確性[2]。

1.2 特征提取
經過預加重和端點檢測之后得到語音段采樣值構成的向量序列。接下來對該向量序列進行特征參數分析,目的是提取合適的語音特征參數,使特征向量序列在語音識別時,類內距離盡量小,類間距離盡量大。特征參數的提取同樣是語音識別的關鍵問題,特征參數的選擇直接影響到語音識別的精度。結合SoPC設計的需求,選擇提取語音信號的美爾特征參數(MFCC)[3]。MFCC能夠較好地反映人耳的聽覺特性。
為求識別系統簡潔,每詞條固定采集3.2 s的語音信號,采樣頻率為8 kHz,經端點檢測切分出語音段,然后將語音段進行分幀(每幀256個采樣點),每幀提取一組14維的MFCC參數,組成一組特征參數向量序列,作為待識別語音段的特征參數。
1.3 模式匹配
對于大詞匯量的非特定人語音識別系統,模式匹配多采用基于模型參數的隱馬爾可夫模型(HMM)的方法或基于非模型參數的矢量量化(VQ)的方法。但是HMM算法模型數據過大,對存儲空間和處理速度的要求高,不適合嵌入式系統。VQ算法雖然訓練和識別的時間較短,對內存要求也較小,但識別性能較差。因此考慮到嵌入式系統系統資源有限以及運算能力限制,而又需要保證識別準確性,決定采用基于動態時間規整的算法(DTW)進行模式匹配。
由于每個人的發音習慣不同,以及同一個人每次說同一個單詞時說話速度具有隨機性,因此會導致每次采樣得到的語音數據序列長度具有隨機性。DTW算法由日本學者板倉(Itakura)提出[4],能夠較好地解決語音識別時單詞長度具有隨機性這一問題。
DTW[5-6]算法將時間規整和距離測度計算相結合,描述如下:
(1)將特征提取部分提取出來的特征向量序列與模板庫中每個詞條的特征向量序列逐幀計算距離,得到距離矩陣。對應幀之間的距離是兩幀的特征向量中對應分量的差值的平方和。距離矩陣中元素的計算式為:
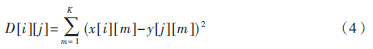
其中,D[i][j]為距離矩陣的元素,表示待識別語音段特征向量序列第i幀和該條參考模板向量序列第j幀之間的距離,i=0,1,2,…,I-1;j=0,1,2,…,J-1。I、J分別為待識別語音的特征向量序列和該條參考模板序列的總幀數。x[i][m]為待識別語音的特征向量序列第i幀向量的第m維分量,y[j][m]為該條參考模板的第j幀向量的第m維分量。K為對切分出的語音段每幀語音的原始采樣數據提取的特征向量的維數,該識別系統中每幀提取14維的MFCC參數,因此K=14。
(2)按照一定的局部判決函數,由距離矩陣計算出累加距離矩陣(求得的累加距離矩陣最末一個元素的值即為待識別語音和該條參考模板之間的總距離),得到累加距離矩陣的同時得出最佳規整路徑[3-4]。圖3所示為設計中采用的三種局部判決函數。

同理,對待測語音與模板庫中的每條模板求得一個統計平均距離。由判決邏輯判斷出各統計平均距離值中的最小值,相應的模板所指向的單詞即為最終的識別結果。
2 系統實現
系統硬件部分如圖4所示,包括FPGA芯片、Flash、SDRAM、音頻編解碼芯片WM8731、按鍵以及LCD1602。在FPGA芯片中添加NiosII軟核CPU,并建立片外Flash、SDRAM、音頻編解碼芯片WM8731和LCD1602的接口部分。
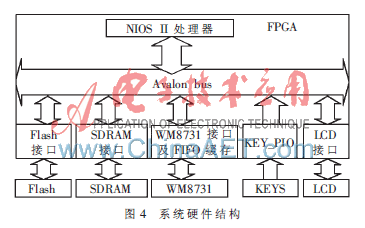
系統中的Flash芯片用于存儲FPGA硬件設計文件、系統初始化所需代碼和用戶程序以及參考模板庫,SDRAM作為系統內存。系統上電后,硬件編程文件以及用戶程序讀入SDRAM中,并且初始化各硬件設備。初始化完畢后,如果選擇系統進入識別模式,CPU通過I2C總線向WM8731寫入命令,控制音頻芯片WM8731采集語音數據并進行A/D轉化,得到的數據經過WM8731的數據輸出端口在FPGA內部構建的FIFO緩存,存入內存中,然后對數據進行后續處理并進行識別,最終輸出識別結果。
系統采用SoPC方法實現,按需要定制硬件模塊,設計過程簡潔靈活,對系統的后續升級維護也比較方便。且實驗表明:(1)采用雙重判決機制進行端點檢測,能夠得到較好的識別效果;(2)采用較簡單的DTW方法進行模式匹配,一方面在消耗系統資源較少的情況下能夠得到較高的識別速度,使得整個系統能夠滿足實時性的要求。另一方面,在模式匹配時采用不同的局部判決函數求得多個累加總距離,進而求得累加總距離的統計平均值。以統計平均值作為最終的判決依據,相對于只采用單一局部判決函數下得到的識別結果理論上可靠性更高。
參考文獻
[1] 周立功.SoPC嵌入式系統基礎教程[M].北京:北京航空航天大學出版社,2008.
[2] 劉華平,李昕,徐柏齡,等.語音信號端點檢測方法綜述及展望[J].計算機應用研究,2008(8):2278-2283.
[3] 羅希,劉錦高.基于NIOS的ANN語音識別系統[J].計算機系統應用,2009(12):144-146.
[4] 趙力.語音信號處理[M].北京:機械工業出版社,2003.
[5] 王娜,劉政連.基于DTW的孤立詞語音識別系統的研究與實現[J].九江學院學報(自然科學版),2010(3):31-39.
[6] 姚天任.數字語音處理[M].武漢:華中科技大學出版社,1991.