
摘 要: 作為云存儲的核心基礎平臺,分布式文件系統的重要性日益凸顯。分布式文件系統中數據存儲在多臺計算機節點上,必然會出現負載均衡問題。首先,對MooseFS的系統架構進行了研究,然后分析了MooseFS分布式文件系統中chunkserver選擇算法,研究了chunkserver算法的負載均衡性能,最后對其進行了改進。經過實驗測試對比,實驗結果顯示改進算法能顯著提高chunkserver的負載均衡性能。
關鍵詞: 分布式文件系統;MooseFS;數據存儲;負載均衡
隨著云計算迅速發展,IT界將進入“云”時代。然而,云計算[1]中會產生海量的數據存儲,傳統的文件系統已不能滿足其性能要求。作為云存儲的核心基礎平臺,分布式文件系統的重要性日益凸顯。目前,互聯網上應用最多的分布式文件系統有GFS[2]、HDFS[3]、MooseFS等。MooseFS分布式文件系統,其設計思想來源于google文件系統,采用的是主從式服務器架構,通過將文件數據分成64 MB的chunk塊分散存儲在多臺通過網絡連接起來的計算機節點上,這種模式不可避免地存在一些節點分配的chunk塊過多,而另外一些節點卻是空閑的,導致系統的chunkserver數據塊分配負載不均衡問題。
數據的負載均衡是分布式文件系統的核心之一,是否有好的負載均衡算法直接影響系統的性能,如果算法沒有選擇好,會導致負載嚴重失衡,使系統的性能不能得到充分的發揮。因此有必要研究chunkserver的數據塊負載均衡選擇算法,以解決chunkserver數據塊分配的負載均衡問題。
1 相關工作
負載均衡[4-5]的實現方法主要有靜態模式和動態模式。靜態模式是指在系統執行前,提前采取相應措施,把數據存儲到各個節點上,盡可能地保證系統運行過程中不出現負載不均衡現象。動態模式是指在系統執行過程中,實時根據節點的存儲狀況來實現負載均衡。很顯然,靜態模式仍然還會有較高的概率出現系統負載不均衡現象,動態模式雖然實現起來比靜態模式復雜,但是執行后效果好。MooseFS分布式文件系統就是采用動態模式來實現chunkserver的負載均衡的。
負載的量化有多種標準,如CPU利用率、內存利用率等。目前,最常見的負載均衡算法有輪轉法、隨機法、散列法、最快響應法[3]等。輪轉法,均衡器將新的請求輪流發給節點表中的下一個節點,是一種絕對平等。隨機法,把偽隨機算法產生的值賦給各節點,具有最大或最小隨機數的節點最有優先權,各個節點的機會也是均等的。散列法也叫哈希法,利用單射不可逆的HASH函數,按照某種規則將新的請求發送到某個節點。最快響應法,平衡器記錄自身到每個節點的網絡響應時間,并將下一個到達的連接請求分配給響應時間最短的節點。
本文以chunkserver上chunk塊的多少作為負載均衡的指標。這里負載均衡是指各個chunkserver上chunk塊數的多少大致相同,不會出現一些chunkserver上塊數很多,而另外一些chunkserver上塊數很少或是沒有塊數,造成一些chunkserver運行繁忙,而一些chunkserver處于空閑狀態的不均衡現象。
2 MooseFS的chunkserver負載均衡算法
Moose File System[6]是一個具備容錯功能的網絡分布式文件系統,它將數據分布在網絡中的不同服務器上,MooseFS通過FUSE使之看起來就是一個Unix的文件系統。即分布在各個范圍的計算機將它們未使用的分區統一進行管理使用的一種文件系統。
2.1 MooseFS文件系統架構
MooseFS分布式文件系統主要由四部分組成[7]:
(1)管理服務器managing server(master):負責各個數據存儲服務器的管理,文件讀寫調度,文件空間回收以及恢復,多節點拷貝。
(2)元數據日志服務器Metalogger server(Metalogger):負責備份master服務器的變化日志文件,文件類型為changelog_ml.*.mfs,以便于在master server出問題的時候接替其進行工作。
(3)數據存儲服務器data servers(chunkservers):負責連接管理服務器,聽從管理服務器調度,提供存儲空間,并為客戶提供數據傳輸。
(4)客戶機掛載使用client computers:通過fuse內核接口掛接遠程管理服務器上所管理的數據存儲服務器,使共享的文件系統和本地unix文件系統的使用效果類似。
2.2 chunkserver負載均衡算法
在MFS系統中,當客戶端向數據存儲服務器上傳文件時,這些被上傳的文件被劃分成64 MB大小的chunk塊,然后再根據chunkserver選擇算法被存儲在數據存儲服務器上。如果chunk塊被均衡分配,則系統不會出現一些chunkserver運行繁忙,而一些chunkserver處于空閑狀態的現象,提高了用戶訪問系統的速度。
MFS源代碼中定義了matoceeerventry結構體,用來描述chunkserver的信息。在這個結構體中有一個carry變量,它是MFS中數據存儲時分布算法的核心。MFS中每臺chunkserver會有自己的carry值,在選擇chunkserver時會將每臺chunkserver按照carry值從大到小做快速排序,優先選擇carry值大的chunkserver來使用。算法流程圖如圖1所示。其中,allcnt表示mfs中可用的chunkserver的個數,availcnt表示mfs中當前可以直接存儲數據的chunkserver的個數,demand表示當前文件的副本數目。
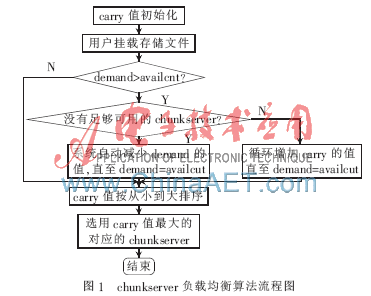
MFS系統啟動時,通過rndu32()函數為每一個chunkserver隨機產生一個大于0且小于1的carry值。系統運行時,每臺chunkserver的carry值的變化滿足以下規律[8]:
(1)僅當carry值大于1時,才可以向此chunkserver中存儲數據,并將此chunkserver的carry值減1。
(2)當demand>availcnt時,循環增加每臺chunkserver對應的carry變量的值,直到滿足demand<availcnt時為止。
(3)變量carry每次增加的增量為本臺chunkserver的總空間與系統中總空間最大chunkserver的總空間的比值。
根據以上算法的分析可知,在MFS系統中,數據并不是均勻地分配到各臺chunkserver上的,而是chunkserver總空間大的,分配到的數據就多,即分配到chunkserver上的數據與此chunkserver的總空間大小成正比。如果chunkserver的總空間大小相同,則數據被均勻分配到chunkserver上,表1為隨機生成500個、1 000個、1 500個、2 000個文件時,chunk塊在各個chunkserver上的分布,測試結果顯示,數據被均勻分配到各個chunkserver上。

2.3 改進的chunkserver負載均衡算法
在MFS系統中,如果chunkserver的總空間大小差別很大,就會造成總空間大的chunkserver被多次選擇,chunk塊數多,而總空間小的chunkserver很少或幾乎不被選擇,chunk塊數少,造成chunk塊分布不均衡。在圖1整個算法流程圖中循環增加可直接存儲數據的chunkserver的個數,即增加carry的值直至demand=availcnt是負載均衡算法的核心部分,而其中carry的增加量servtab[allcnt].w如何計算是算法的關鍵問題。增加可直接存儲數據的chunkserver的流程圖如圖2所示,算法實現代碼如下:
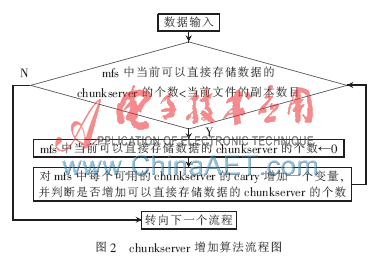
在原算法中carry的增加量servtab[allcnt].w=(double)eptr->totalspace/(double)maxtotalspace,就是把本臺chunkserver的總空間與系統中總空間最大chunkserver的總空間的比值作為carry變量的增加量。而改進后carry的增加量servtab[allcnt].w=((double)maxtotalspace-(double)eptr->usedspace)/(double)maxtotalspace,就是把系統中總空間最大chunkserver的總空間減去本臺chunkserver已用去的空間大小后與系統中總空間最大chunkserver的總空間的比值作為carry變量的增加量。
2.4 對改進負載均衡算法的測試
本測試的實驗環境是在VMware里虛擬出5臺虛擬機,1臺master,3臺chunkserver,1臺client。其中,3臺chunkserver的硬盤大小分別為5 GB,8 GB,11 GB,其他配置均相同。測試的主要目的是檢測改進的算法是否能將數據均勻地存儲到各臺chunkserver上,此時系統的冗余備份設置為1。
client的掛載目錄為/mnt/mfs/test。測試腳本為:
#!/bin/bash
for((i=0;i<1000;i++))
do
dd if=/dev/zero of test“$i” bs=“$RANDOM”
count=1
cp test“$i”/mnt/mfs/test
done
利用測試腳本隨機生成1 000個隨機文件,然后上傳到MFS系統中。算法改進前后chunk塊的分布情況如表2和表3所示。
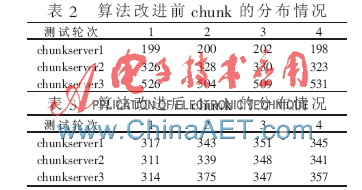
實驗分別對改進前和改進后做了4次測試。從測試結果可以看出,算法改進前chunkserver硬盤容量越大,其上數據的分布就越多,這種情況容易導致各臺chunkserver上的訪問壓力不一樣,使系統性能不能達到最優。算法改進后,數據在chunkserver上基本是平均分配,各臺chunkserver訪問壓力也基本一致,避免了總空間大的chunkerver總被不停地訪問,而總空間小的chunkserver被閑置,使系統性能得到了優化。
本文對MooseFS分布式文件系統進行了分析,針對chunkserver選擇算法存在負載不均衡的不足進行了改進,避免出現系統中總空間大的chunkserver上存儲chunk塊數多、訪問量大,而總空間小的chunkserver上存儲的chunk塊數少或沒有chunk塊存數而處于閑置狀態。通過實驗測試,改進后達到了預期的效果,chunk塊在各個chunkserver上分布均衡,系統性能得到優化。
參考文獻
[1] 王德政,申山宏,周寧寧.云計算環境下的數據存儲[J].計算機技術與發展,2011,21(4):81-82.
[2] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google file system[C]. Proceedings of the 19th ACM Symposium on Operating Systems Principles.Lake George,New York:2003:29-43.
[3] APACHE HADOOP.Hadoop[EB/OL].[2009-03-06].(2012-03-19)http://hadoop.apache.org/.
[4] 譚支鵬.對象存儲系統副本管理研究[D].武漢:華中科技大學,2008.
[5] 張聰萍,尹建偉.分布式文件系統的動態負載均衡算法[J].小型微型計算機系統,2011,32(7):1424-1426.
[6] 百度文庫.MFS文檔[DB/OL].2010.http://wenku.baidu.com/view/320b56260722192e4536f61b.html.
[7] 51CT0博客.MooseFS介紹[DB/OL].2011.http://haiquan517.blog.51cto.com/165507/526252.
[8] mfs(mooseFS)深入分析(chunkserver選擇算法)[DB/OL].2011.http://www.oratea.net/?p=285#comment-481.