
摘 要: 為了提高Huffman解碼的效率和實時性,采用并行處理技術和改進的Huffman并行解碼算法,設計基于現場可編程門陣列FPGA的Huffman并行解碼器。在不考慮Huffman編碼長度的情況下,解碼器通過插入流水線結構的方法將Huffman碼流的碼流頭和信息碼流分開,同時進行解碼。硬件仿真結果表明,在一個時鐘節拍內解碼器處理的數據位數與解碼效率成正比,位數越多,實時性越好。
關鍵詞: Huffman解碼;并行解碼器;碼流頭;流水線結構
在靜止圖像和運動視頻的壓縮方法中,由于信息量大、速率快,使得編解碼效率的提高迫在眉睫。最常用的編解碼方式是基于可變長編碼VLC(Variable-Length Code)的Huffman編解碼[1]。與編碼相比,并行Huffman解碼較復雜。其實時性不僅要提高時鐘頻率,還需要從算法、硬件優化的角度提高。
通過改進文獻的Huffman解碼算法[2-3],在原有基礎的解碼中加入流水線結構。針對參考文獻[4]中Huffman編碼方式設計并實現了一種能夠節省碼字存儲空間的、可以提高解碼速度的并行Huffman解碼方式。
1 Huffman并行解碼算法改進
Huffman并行解碼方式可以彌補查找表過大引起硬件開銷大的不足。與并行解碼算法相比[5-7],本算法在解碼結構中插入流水線,在并行解碼方式中,當頭碼流分析結束時,輸入到解碼器中的信息碼采用并行多路檢測,得到地址偏移量和最小編碼的長度。在每個時鐘周期內,都會輸出一個解碼信息碼。Huffman并行解碼器總的處理過程如圖1所示。

2 JPEG中的Huffman并行解碼設計
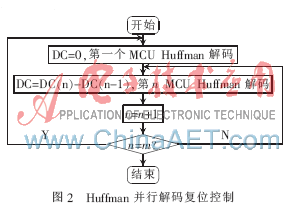
在碼流分析中可以得到Huffman編碼時的相關信息,即相同長度的最小編碼、最小編碼的個數和Huffman編碼相關值,并分別存入對應的存儲器中,再把相應的地址存入16×8存儲器里,編碼相關值則存入256×8的寄存器中。還需設定Huffman解碼的重啟間隔,這由JPEG的DC差值編碼決定。為了防止解碼中造成較大的誤差,每解碼m比特就需對DC進行清零,其中m為重啟間隔度量值。Huffman并行解碼復位控制如圖2所示。
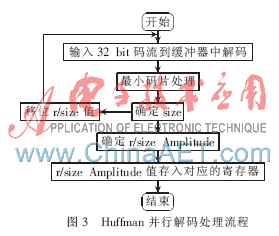
在碼流分析中,確定Huffman并行解碼的相關信息后進行解碼。對JPEG來說,最終要找到AC=0的個數Run、AC的位數Size和幅度Amplitude,以及DC的Size和Amplitude。在JPEG中,AC和DC分別是交流系數和直流系數,其中AC和DC各自又包含色度和亮度。進行一次Huffman并行解碼處理流程是整個Huffman并行解碼器的關鍵流程之一,處理流程如圖3所示。
輸入碼流的關鍵處理是在輸入并行多路檢測上,它可以同時處理當前對應的最小編碼長度、最小編碼的解碼及其地址偏移量。通過對輸入碼流的處理,最終得到Huffman并行解碼所需要最小編碼的Run、Size、Amplitude信息,其并行多路實現方式如圖4所示。獲得當前編碼的寬度提供給當前解碼器使用。在當前編碼進行對應的最小編碼的處理時,同時與在碼流分析中得到的存入存儲器的最小編碼進行比較,確定當前碼流解碼需要的間隔。其具體過程如圖5所示,其中DC、AC就是從碼流分析中存入存儲器的。解碼獲得Run、Size及Amplitude的實現流程方式如圖6、7所示。但是要注意DC中Huffman并行解碼只能得到相應最小編碼的Size和Amplitude。而在AC中Huffman并行解碼可以得到相應最小編碼的Run、Size及Amplitude。
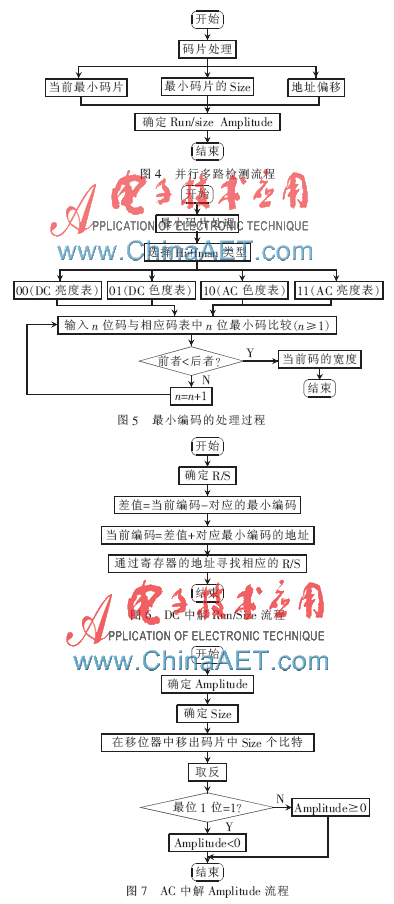
關于解碼DC中獲得R/S,采用相對地址和絕對地址尋址,即當前最小編碼的地址=基本最小編碼地址+相對地址(差值)。對不同的4種碼表,第一個編碼的基本地址都是固定的,由于DC中個數最大值為126,而AC中個數最大值為162。因此將第一個亮度DC地址設為0,第一個亮度AC地址的設為12;第一個色度DC地址設為114,第一個色度AC地址為156。對于不同長度編碼同一分量的最小地址,直接采用該分量第一個編碼地址與小于該長度編碼個數的和。從待解碼數據流的輸入到確定R/S、Amplitude,都采用并行多路檢測的方法。與串行解碼方式相比大大提高了碼流的解碼速度。
在并行Huffman解碼結構中,處理了幾位編碼后,補上相應個數的新的待解編碼,補充的位數是由Size和Amplitude值決定的。由于每次解碼碼長的不確定性,本文采用桶型移位寄存器,但是會占有一定的面積資源。因為每次移位的位數也是不確定的,所以必須要考慮移位溢出的情況。設計中選用32位移位寄存器和16位桶型移位寄存器,前者相當于一個緩存器,其[15:0]的后半段寄存器進行解碼操作,[31:16]后半段寄存器存入桶型移位寄存器中。當最小編碼等于16時,Amplitude值從桶型寄存器中移出;若操作編碼流長度大于16,需要由32位寄存器對它進行移位補位,[15:0]和[31:16]共同移位。當移位位數超過48時,設計一個累加器向外輸出碼流輸入允許信號,繼續輸入碼流到32位寄存器中。此外,輸入解碼器數據位寬在0~32范圍內變化,實際輸入的待解碼數據位寬將取決于該編碼數據在Huffman編碼樹中的位置。
3 Huffman并行解碼的實現
將Run、Size及Amplitude值存入相應的寄存器后,為JPEG后續的解碼做準備。同時也就完成了一次Huffman并行解碼,所有的解碼處理過程都是同步進行的。經過驗證,Huffman并行解碼處理過程是在一個時鐘周期內實現解一個編碼。由于FPGA實現,需采用很多組合邏輯,因此關鍵路徑的延時必須考慮在內[8-9]。同時該硬件實現中也用到了許多存儲器,所以會占有一定FPGA的面積資源,與串行解碼相比,在速度上和輸出的穩定性上有一定的優勢。其中具體環節的硬件實現框架如圖8所示。
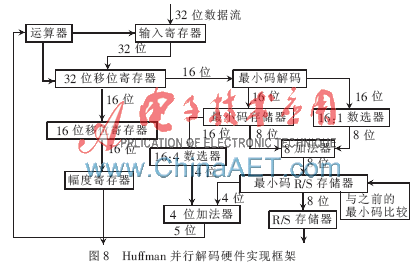
圖8中各模塊的性能為:
(1)16位最小碼存儲器。存放的是DC和AC的最小編碼。
(2)16位最小碼解碼模塊。輸入的16位待解碼流與最小編碼進行比較,找到相同長度的最小編碼,輸出Huffman最小編碼到R/S存儲器,輸出與相應最小編碼同等長度的實際碼子到數選器[10]。
(3)16:1數選器。差值=實際編碼長度-最小編碼長度。
(4)16位最小碼存儲器。預存的最小編碼地址,16×8的寄存器。
(5)8位加法器。最小編碼的地址+差值=實際編碼的地址。
(6)最小碼R/S存儲器。預存R/S和所有與Huffman相對應的值在256×8的寄存器中,最終解碼解出相應的R/S。
(7)16:4數選器。把16位編碼的長度換成4位表示。
(8)4位加法器。最小編碼的長度+差值Size=解碼時一共處理的位數,即需要補入數據流的位數。
(9)運算器。累加器是將移位的總位數進行相加,并向移位器提供當前移位位數。當總數≥16時,輸出輸入數據允許信號,請求前置模塊輸入數據,在輸入允許信號有效時,刷新運算器的值;當總數≥32時,輸入允許信號仍未有效,則終止后續的操作。
(10)32移位寄存器。對輸入數據進行存儲和移位。
(11)16移位寄存器。移出幅度的值,選用桶型移位寄存器的原因是當移出位數>16時也可以處理。
與串行解碼相比,Huffman并行解碼算法的優點是在一個時鐘周期內,無論Huffman編碼的長度是多少,都可以正確解出編碼信息。數據處理速度的提高,顯然會伴隨硬件FPGA設計的復雜度的增加。本文采用并行處理技術給出了Huffman解碼算法,實現了Huffman并行解碼器的設計。不但能夠在一個時鐘節拍內處理多比特數據,而且節省了存儲空間,克服了Huffman串行解碼實時性差的不足。顯然,本算法的實現是在提高處理數據速度的同時,增加了FPGA硬件的面積資源。
參考文獻
[1] 宋奇剛,魏小義.霍夫曼解碼器的設計及在MP3解碼中的應用[J].今日電子,2005(3):10-12.
[2] 李曉飛.Huffman編解碼及其快速算法研究[J].現在電子技術,2009(21):102-108.
[3] 陳亞光,陳少平,朱翠濤,等.并行Huffman解碼器算法分析[J].計算機測量與控制,2002,10(6):418-420.
[4] 雒莎,葛海波.基于查找表的自適應Huffman編碼算法[J].西安郵電學院報,2011,16(5):76-79.
[5] 楊浪花,張濤,于鳳萍,等.MP3/AAC解碼器中Huffman硬件加速器設計與實現[J].電聲技術,2010(6):55-59.
[6] 陳佳昕,林濤.一種優化了的并行Huffman解碼器[J].有線電視技術,2007(8):47-50.
[7] 方嬋嬋,葉兵,吳彪,等.Huffman并行解碼結構及硬件實現[J].合肥工業大學學報,2007,30(7):855-857.
[8] 傅祖蕓.信息論基礎理論與應用[M].北京:電子工業出版社,2001.
[9] 馬建國,孟憲元.FPGA現代數字系統設計(第1版)[M].北京:清華大學出版社,2010.
[10] PALNITKAR S.Verilog HDL數字設計與綜合(第2版)[M].夏宇聞,胡燕祥,刁嵐松,等譯.北京:電子工業出版社,2009.