
摘 要: 面對電子商務模式下電商對客戶競爭的現狀,針對傳統的客戶分類方法的不足,設計了一種基于FCM模糊聚類算法客戶分類的并行算法。實驗結果表明設計的方法能準確地對電商客戶分類,在MATLAB集群下并行算法的運行取得了明顯的并行效果。
關鍵詞: 電子商務客戶分類;FCM算法;MATLAB集群并行
市場經濟的發展和網絡技術的革新促使電子商務迅速普及。在競爭激烈的電子商務經濟模式下,客戶成為電商競爭的焦點。電商想要對客戶進行分析需要將客戶分類,找出優質客戶、挖掘潛在客戶才能制定出針對性的營銷策略。電商客戶分類是指根據客戶的歷史交易情況將客戶群劃分為不同的等級,從中找出共同的要素并對客戶的消費需求及消費行為進行研究,制定并實施有效的銷售策略。
傳統的客戶分類方法是基于經驗或簡單統計方法[1],依據電商客戶歷史交易數據對客戶過去和現在價值進行分析,忽略了客戶的潛在價值和未來價值。這兩種方法分類主觀性強,與分類標準的關聯性大,分類效果不理想。FCM模糊聚類算法是多元統計算法中廣泛應用于經濟分析的算法,它是在聚類分析算法的基礎上,增加“隸屬度”,用數學的方法定量地確定每一個樣本點與各個類別的親疏關系,分類結果客觀。此外,面對電商網站運營產生的海量歷史交易數據,本文利用MATLAB集群可以發揮其適合執行數據密集型任務的優勢,解決“數據大,計算難”的問題,高效地計算出聚類結果。
本文基于FCM模糊聚類算法設計了一個針對電商客戶分類的方法,以電商網站凡客誠品的歷史交易數據為例進行實驗測試設計方法的有效性。同時在MATLAB集群中針對3個規模不同的數據進行并行計算實驗,做并行化研究。實驗結果表明FCM模糊聚類算法能夠準確地將電子商務客戶分類,利用MATLAB集群的多個節點并行計算數據,縮減了計算數據時間。
1 電子商務網站客戶分類算法
1.1電子商務網站客戶分類
電子商務客戶分類是電商在收集和整理客戶交易信息的基礎上,按照客戶交易記錄把某一類的客戶分到一個群體的過程,其原理如圖1所示。

首先收集電子商務客戶的原始交易記錄數據,利用電子商務后臺數據或者爬蟲技術爬取。其次是數據預處理環節,要對收集的數據進行規約和清洗,刪除其中沒有用處的數據。最后通過FCM模糊聚類算法對輸入數據進行聚類分析,獲得聚類分析結果。電商可以針對不同消費群體制定指定的銷售策略,實現穩定盈利。
1.2 FCM模糊聚類算法
K-means聚類分析算法是依據實驗數據本身具備的定性或定量的特征來對數據進行分組歸類的方法,方便了解數據集的內在結構,是數據挖掘的主要數據分析方法[2]。算法優勢是操作簡單、聚類速度快。算法存在的缺陷是容易陷入局部最優值,這樣獲得的聚類結果是局部最優解而不是全局最優解。由于K-means聚類分析算法的缺陷,用于電子商務客戶分類的聚類效果不理想。
模糊聚類分析算法FCM(Fuzzy C-Means algorithm)是在K-means聚類分析算法的基礎之上,增加“隸屬度”,用數學方法定量地確定樣本點與其他各個樣本的親疏關系,客觀地劃分樣本集類型。能夠客觀地計算出每一個客戶屬于各類樣本的概率,分析效果更加精確[3]。FCM模糊聚類算法步驟如下:
FCM模糊聚類分析算法的目標函數是:


表1是實驗取得的隸屬度矩陣表,結尾保留4位有效小數。列代表客戶編號,行代表4個類別。對應的數值就是每一個客戶屬于每一類的概率。每一列概率數值相加之和為1,代表概率越大,屬于那一類的可能性越大。
2.2 舉例實驗分析
本文先后分別對這100個客戶數據進行聚類,分為3類、4類和5類。結果如圖4和圖5所示。
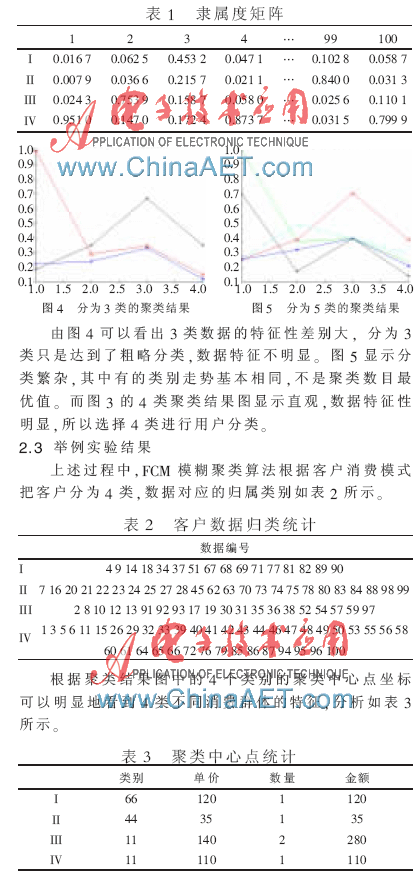
第一類潛在客戶:該類消費群體關心價格,喜歡打折促銷。流失傾向偏大,對網站信任度低。雖然具有一定的價值,但給企業帶來的利潤小。
第二類小客戶:該群體主要購買飾品,企業從這類消費群體可以獲得的利潤較小。流失傾向偏小,應該通過營銷方法使其成為一般客戶。維持該類客戶對電子商務的發展仍具有一定的意義。
第三類優質客戶:群體主要購買服裝,這類群體是企業可以從中獲得利潤最大的群體。該類群體購買優質產品,且購買的數量多,是企業的高端顧客。該網站的客戶忠誠度高,在一定時間內購買的商品種類和交易數量多,是企業需要重點維護的對象。
第四類一般客戶群體:主要購買服裝,該類客戶偏向于購買普通服裝,電商的該類客戶數量最多。對網站的產品持肯定態度,雖然沒有為電商提供高利潤,但是交易會穩定持續地進行,是企業穩定生存的基礎。
3 MATLAB集群并行化
MATLAB是一套高性能的數值計算和可視化軟件,集數值分析、矩陣運算、圖形處理和信號處理于一體。MATLAB最大的優勢在于它的強大的科學計算能力,專用工具箱具備全面的數學函數,能夠執行數據復雜型任務和數據密集型任務[4]。
(1)實驗環境:由3臺PC機搭建的MATLAB集群。硬件配置:Intel(R)Core(TM)、[email protected] GHz(2CPUs),2 GB內存。軟件配置:系統環境Windows XP、MATLAB(R2011b)。文件大小:規模大小為1 GB、2.2 GB、3 GB的3個數據表。
(2)實驗結果及分析:本文采用數據分割的方式對FCM模糊聚類算法進行集群并行計算。實驗分別在單節點與多節點環境下執行,首先在雙節點環境下的運行時間小于單節點下運行的時間,并行效果明顯。其次又分別在4個節點與6個節點下分別執行聚類計算,實驗結果表明時間縮短的增量與集群節點數目成正比,隨著集群節點的增加而增大。說明用MATLAB集群來處理本文的數據是有效的,發揮了MATLAB集群處理數據密集型任務的優勢,體現了MATLAB集群的高性能。實驗結果如表4所示。
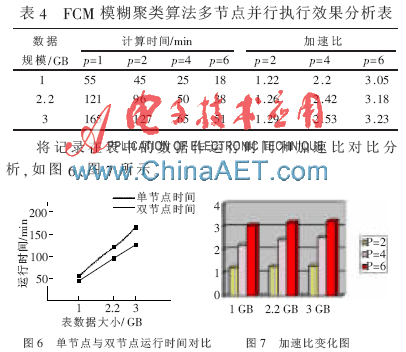
通過對圖6單節點與雙節點環境下運行時間的對比,可以看出并行計算時間短于串行計算的時間,且隨著數據規模的加大,時間縮短增量逐漸提高。圖7顯現了加速比的變化,不同規模大小數據的加速比均隨著集群節點數目的增大而增大。由此可以證實,FCM模糊聚類算法在并行集群中應用于電子商務客戶分類適用,能夠取得良好的并行效果,輸出結果時間縮短。充分說明了FCM模糊聚類算法并行化的可行性和MATLAB集群的高性能性。
電子商務處于蓬勃發展階段,如何準確有效地對消費客戶進行分類并制定針對性的營銷策略是其盈利的關鍵。本文針對這一現實問題,選定多元統計分析中的FCM模糊聚類算法進行客戶分類并做了并行化研究。實驗結果表明,在MATLAB集群中運行并行后的FCM模糊聚類算法能夠取得良好的并行效率,同時也驗證了MATLAB集群在處理數據密集型任務的高效性。本文設計的方法可以應用于電子商務中,對電子商務客戶分析方面有一定的實際意義。
參考文獻
[1] 朱晶晶.電子商務網站分類體系理解的用戶心智模型研究[D].南京:南京理工大學,2010.
[2] SELIM S Z. K-Means-type algorithms: A generalized convergence theorem and characterization of local optimality[J]. IEEE Transactions on Pattern Analysis and Machine Intelligce, 1984,6(1): 81-87.
[3] DUNN J C. A fuzzy relative of the IOSDATA process and its use in detecting compact well separated clusters[J].Cybemet.3,197:32-57.
[4] MathWorks. MATLAB Distributed Computing Server 5 System Administrator′s Guide[EB/OL]. http://www.mathworks.com/access/helpdesk/help/pdf_doc/mdce/mdce.pdf, 2010.
[5] 徐瑞,黃兆東,閻鳳玉.MATLAB2007科學計算與工程分析[M].北京:科學出版社,2008.
[6] 瞿小寧.K均值聚類算法在商業銀行客戶分類中的應用[J].計算機仿真,2011,28(6):357-360.
[7] 李容.基于K均值聚類算法的圖書商品推薦仿真系統[J].計算機仿真,2010,27(6):346-349.