
高速移動下OFDM均衡器的FPGA實現
王 歡 楊 揚
來源:現代電子技術
摘要: 本文主要討論基于Xilinx公司Virtex-2 FPGA硬件平臺的均衡器算法中矩陣求逆的運算過程實現。將程序下載到FPGA,并通過RS 232將結果數據回送到主機查看和驗證。
Abstract:
Key words :
0 引言
正交頻分復用(OFDM)是一種正交多載波調制技術,它將寬帶頻率選擇性衰落信道轉換成一系列窄帶平坦衰落信道,在克服信道多徑衰落所引起的碼間干擾,實現高數據傳輸等方面具有獨特的優勢。但是由于OFDM信號頻譜重疊,對信道變化很敏感,在高速移動下,信道的時變特性更加明顯,此時OFDM系統載波間的正交性會遭到破壞,出現載波間干擾(ICI),這會導致系統性能明顯降低。為了消除ICI,必須采用適當的均衡技術以補償ICI。國內外許多學者對這些問題進行了大量的研究,提出了各種不同的方法,得到了一些階段性成果。文獻提出了一種低復雜度的迭代MMSE均衡器算法,在保證均衡效果的同時把運算量成功降低到o(N),為該均衡器算法的實際運用奠定了基礎。
現場可編程門陣列(Field Programmable Gate Array,FPGA)器件近年來取得了飛速的發展,已經具有強大的計算性能和邏輯實現能力。特別是Xilinx公司的FPGA具有豐富的IP資源,容量大且具有強大的軟件支持,在各個領域得到了廣泛的應用。本文主要討論基于Xilinx公司Virtex-2 FPGA硬件平臺的均衡器算法中矩陣求逆的運算過程實現。將程序下載到FPGA,并通過RS 232將結果數據回送到主機查看和驗證。
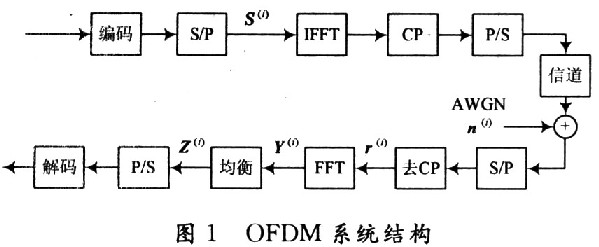
1 時變信道中OFDM系統均衡器
1.1 時變信道中的OFDM系統結構
考慮一個載波數為N的OFDM系統如圖1所示,假設完全同步,并且有足夠長(不小于信道階數)的循環前綴(CP)。在去除了循環前綴CP以后第i個數據幀收到的數據矢量為:
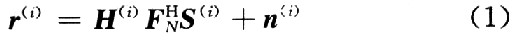
式中:
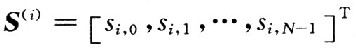 OFDM第i個數據幀的輸出數據矢量;
OFDM第i個數據幀的輸出數據矢量;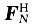 為N點快速傅里葉逆變換矩陣;,n(i)為信道噪聲矢量,定義方差是σ2的高斯白噪聲(AWGN);H(i)是一個N×N的時域轉移矩陣,其元素為
為N點快速傅里葉逆變換矩陣;,n(i)為信道噪聲矢量,定義方差是σ2的高斯白噪聲(AWGN);H(i)是一個N×N的時域轉移矩陣,其元素為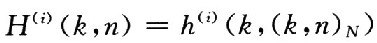 ,其中h(i)(k,n)是描述信道特性的沖擊響應。在接收端,對r(i)進行N點快速傅里葉變換,其輸出為:
,其中h(i)(k,n)是描述信道特性的沖擊響應。在接收端,對r(i)進行N點快速傅里葉變換,其輸出為: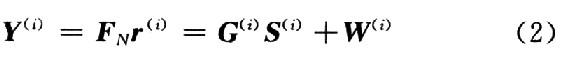
式中: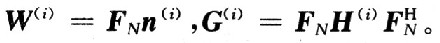
由于在高速移動的環境下,接收信號會受到ICI的影響,故在整個系統中添加均衡模塊,假設均衡器用E(i)來表示,則均衡后的信號可以表示為:
由于在高速移動的環境下,接收信號會受到ICI的影響,故在整個系統中添加均衡模塊,假設均衡器用E(i)來表示,則均衡后的信號可以表示為:
1.2 MMSE均衡器算法
把上面式中的i去掉,根據最小均方誤差的規則,可以簡寫得到均衡矩陣為:
把上面式中的i去掉,根據最小均方誤差的規則,可以簡寫得到均衡矩陣為:
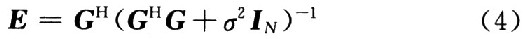
在時變信道中,G不是對角矩陣,則矩陣求逆的直接算法的運算量為o(N3),利用文獻給出的結論:ICI主要來自相鄰的幾個子載波,并且每個子載波的符號能量主要泄漏至鄰近的少數子載波上,也就是說,G中的很大一部分元素是可以忽略的。然后再采用迭代的方法對矩陣求逆,把運算量降為o(N2),但是在實際應用中,N是一個較大的數值,這個方法計算量仍然很大,所以很多算法在考慮均衡效果的同時也盡量減少運算量,以增強算法的可實現性和最終均衡的實時性。
根據Chen等驗證得到G可以被進一步簡化成如下Ak來描述:
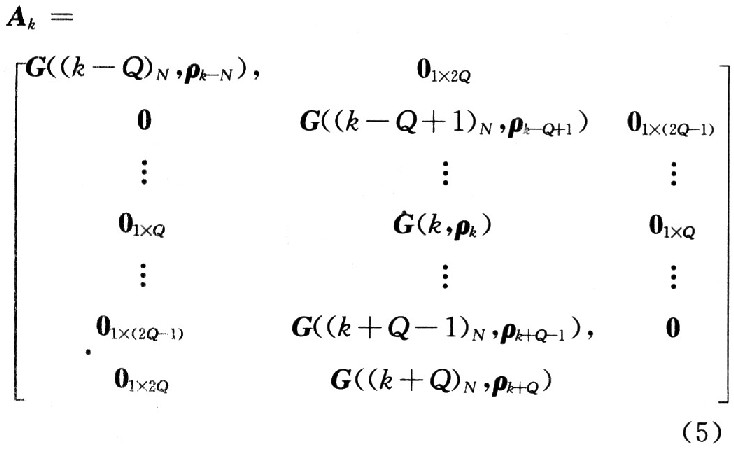
式中:pn是一個由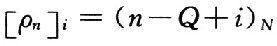 構成的1×(2Q+1)的矩陣,i=O,1,…,2Q。MMSE均衡器可以描述為
構成的1×(2Q+1)的矩陣,i=O,1,…,2Q。MMSE均衡器可以描述為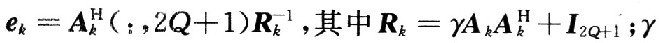 ;γ為該信道的信噪比,且
;γ為該信道的信噪比,且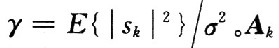 。Ak是一個(2Q+1)×(4Q+1)的矩陣,再利用文獻中迭代的方法來計算矩陣的逆。
。Ak是一個(2Q+1)×(4Q+1)的矩陣,再利用文獻中迭代的方法來計算矩陣的逆。
2 均衡器算法的FPGA實現
當載波數比較大時,OFDM均衡算法所要計算的矩陣比較龐大,計算量大,很難保證實時性的要求。于是人們很自然地會想到用實時性很強的FPGA來實現均衡器的設計,但是均衡本身所需要處理的數據量和運算量都非常大,即使使用FPGA實現也很困難。
若采用文獻中的算法運算量是o(N2),假如當載波數N=128時,運算量還是很大的,無法保證實時性。從均衡效果和運算量兩方面考慮,采用了文獻中的算法。這是一種典型的迭代算法,效果與文獻算法相接近,但是在計算中避免了求一個很大的矩陣的逆運算,而是從頻域轉移矩陣G中提取出了不大的有效矩陣,這樣就減少了大量運算。
2.1 硬件設計思想
在對均衡器算法進行FPGA設計之前,先用Matlab仿真該均衡器浮點算法,通過分析程序可以發現,該算法的核心部分是迭代求逆矩陣的過程。該算法的瓶頸主要是求解由復數元素組成的矩陣的逆的計算量巨大,而且是浮點數會占用很大的存儲空間。為盡量減少需要使用的邏輯資源,在進行ISE設計時,數據用16位定點數表示,其中高8位是整數部分,低8位是小數部分。
2.1.1 硬件設計框圖
實現該均衡器的硬件設計框圖如圖2所示,其中G為從Matlab中產生的頻域轉移矩陣,控制模塊完成從G中取出對應的有效值得到Ak,并且控制當一組運算完成后運用上一組產生的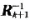 。進行下一組運算,CIR是該算法的核心,即矩陣迭代求逆的運算,CPE模塊是一個簡單的矩陣運算模塊完成
。進行下一組運算,CIR是該算法的核心,即矩陣迭代求逆的運算,CPE模塊是一個簡單的矩陣運算模塊完成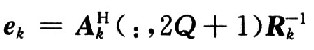 的運算。
的運算。
構成的1×(2Q+1)的矩陣,i=O,1,…,2Q。MMSE均衡器可以描述為;γ為該信道的信噪比,且。Ak是一個(2Q+1)×(4Q+1)的矩陣,再利用文獻中迭代的方法來計算矩陣的逆。 2 均衡器算法的FPGA實現
當載波數比較大時,OFDM均衡算法所要計算的矩陣比較龐大,計算量大,很難保證實時性的要求。于是人們很自然地會想到用實時性很強的FPGA來實現均衡器的設計,但是均衡本身所需要處理的數據量和運算量都非常大,即使使用FPGA實現也很困難。
若采用文獻中的算法運算量是o(N2),假如當載波數N=128時,運算量還是很大的,無法保證實時性。從均衡效果和運算量兩方面考慮,采用了文獻中的算法。這是一種典型的迭代算法,效果與文獻算法相接近,但是在計算中避免了求一個很大的矩陣的逆運算,而是從頻域轉移矩陣G中提取出了不大的有效矩陣,這樣就減少了大量運算。
2.1 硬件設計思想
在對均衡器算法進行FPGA設計之前,先用Matlab仿真該均衡器浮點算法,通過分析程序可以發現,該算法的核心部分是迭代求逆矩陣的過程。該算法的瓶頸主要是求解由復數元素組成的矩陣的逆的計算量巨大,而且是浮點數會占用很大的存儲空間。為盡量減少需要使用的邏輯資源,在進行ISE設計時,數據用16位定點數表示,其中高8位是整數部分,低8位是小數部分。
2.1.1 硬件設計框圖
實現該均衡器的硬件設計框圖如圖2所示,其中G為從Matlab中產生的頻域轉移矩陣,控制模塊完成從G中取出對應的有效值得到Ak,并且控制當一組運算完成后運用上一組產生的
。進行下一組運算,CIR是該算法的核心,即矩陣迭代求逆的運算,CPE模塊是一個簡單的矩陣運算模塊完成的運算。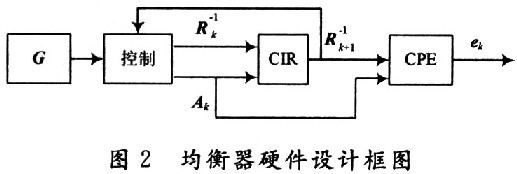
2.1.2 CIR模塊介紹
CIR模塊完成矩陣迭代運算過程,它從輸入端口讀入Ak以及對應的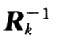 ,采用迭代的方法計算出
,采用迭代的方法計算出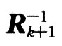 ,用FPGA實現這個模塊的端口如圖3所示。
,用FPGA實現這個模塊的端口如圖3所示。
CIR模塊完成矩陣迭代運算過程,它從輸入端口讀入Ak以及對應的
,采用迭代的方法計算出,用FPGA實現這個模塊的端口如圖3所示。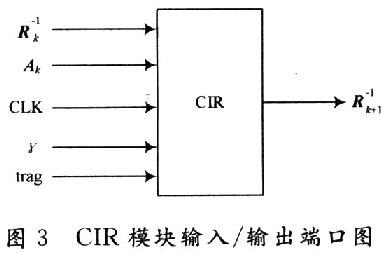
其中,CLK為時鐘;γ是模擬信道的信噪比;Ak是頻域轉移矩陣G中取出的有效矩陣;trag是控制信號,當一次運算結束產生一個有效的
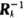 后,只有trag被置為高電平才會進行下一次運算。取Q=2時,是一個5×5的矩陣。整個求逆矩陣的迭代過程就是從前一個5×5的逆矩陣(即)和從頻域轉移矩陣G中對應區域取得的5×9的矩陣Ak運算出下一個5×5逆矩陣(即
后,只有trag被置為高電平才會進行下一次運算。取Q=2時,是一個5×5的矩陣。整個求逆矩陣的迭代過程就是從前一個5×5的逆矩陣(即)和從頻域轉移矩陣G中對應區域取得的5×9的矩陣Ak運算出下一個5×5逆矩陣(即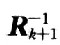 )的過程。
)的過程。
分析其矩陣求逆的迭代算法可以發現,其中大部分完成的是復數矩陣的乘加運算,所有數據是復數,雖然復雜很多,但是實際運算中有許多是多余的。Rk是共軛對稱矩陣,上三角部分和下三角部分的實部相同,虛部也只是正負相反,所以只需要算出上三角矩陣的數據,下三角的部分直接對虛部取反就可以了。
Xilinx的FPGA芯片中集成了硬核的乘加器DSP48,可以方便、高速地進行乘加運算。但是本算法中涉及到的復數運算比較靈活,還包括一些減法運算,直接使用DSP48不是很方便的控制。故設計了一種乘加器,使用了乘法器的IP Core,按照要求設置輸入輸出數據位數,其中的一個乘加運算中設置乘法器的兩路輸入為8位,輸出為16位,調用IP Core如下所示,算法中其他的矩陣運算也都與此類似。
Xilinx的FPGA芯片中集成了硬核的乘加器DSP48,可以方便、高速地進行乘加運算。但是本算法中涉及到的復數運算比較靈活,還包括一些減法運算,直接使用DSP48不是很方便的控制。故設計了一種乘加器,使用了乘法器的IP Core,按照要求設置輸入輸出數據位數,其中的一個乘加運算中設置乘法器的兩路輸入為8位,輸出為16位,調用IP Core如下所示,算法中其他的矩陣運算也都與此類似。

a,b作為兩個寄存器儲存參與運算的數據,outl是乘法器計算的結果,用fcl進行存放,相累加得到f1,再按照共軛復數運算的規律得到nfl。實現一個8位×8位的乘加器共消耗了56個Slice,32個LUT和49個IOB。該乘加器綜合后的RTL結構圖如圖4所示。
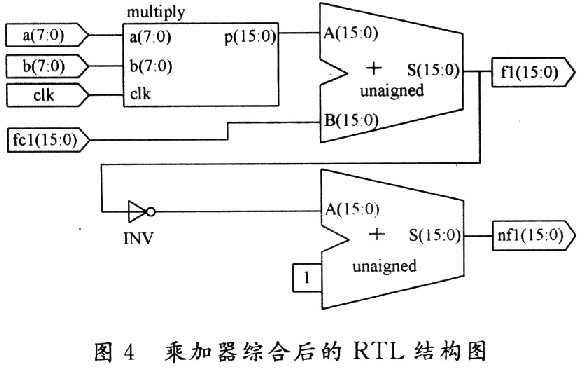
為了能最大限度地提高運算速度,所有數據都用可編程邏輯單元構成的分布式存儲器存儲并列存儲,并且根據算法的要求實現的是多個乘加器同時運算,這樣雖然使用了很多邏輯資源,但任何數據都可以即取即用,便于進行大量的并行運算,以提高運算速度。
2.2 系統驗證仿真
本系統采用Xilinx公司Virtex-2實驗板進行仿真驗證,該實驗板采用的是XC2VP30芯片,它有30 816個邏輯單元,136個18位乘法器,2 448 KbRAM,資源豐富。開發軟件為該公司的集成開發軟件平臺ISE
9.2,HDL語言采用Verilog,使用Matlab輔助ISE完成FPGA設計的方法。通過實驗板上的RS 232串口與PC機進行通信,用Matlab從計算機中傳輸數據到FPGA芯片中,運算后再通過串口回傳均衡后的信號數據到Matlab中仿真驗證星座圖,以判斷該均衡器的效果。
2.2.1 均衡過程
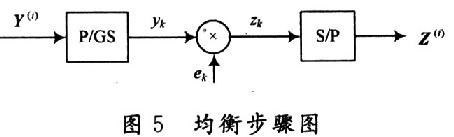
CIR中使用迭代算法避免了并行大向量和大矩陣的運算,而是分步運算。所以對輸入信號進行均衡,首先要進行并串變換,但是不需要變成真正的串行信號。當Q=2時,實際上對需要均衡的輸入信號Y(i)每次取出5個數據,用yk表示,暫且將這樣的變換叫作分組并串變換(P/GS),然后均衡矩陣ek與yk分組完成乘法運算得到一個zk,zk是一個數據不是向量,最后進行串并變換就得到均衡后的信號向量Z(i)。整個均衡的過程如圖5所示。
2.2 系統驗證仿真
本系統采用Xilinx公司Virtex-2實驗板進行仿真驗證,該實驗板采用的是XC2VP30芯片,它有30 816個邏輯單元,136個18位乘法器,2 448 KbRAM,資源豐富。開發軟件為該公司的集成開發軟件平臺ISE
9.2,HDL語言采用Verilog,使用Matlab輔助ISE完成FPGA設計的方法。通過實驗板上的RS 232串口與PC機進行通信,用Matlab從計算機中傳輸數據到FPGA芯片中,運算后再通過串口回傳均衡后的信號數據到Matlab中仿真驗證星座圖,以判斷該均衡器的效果。
2.2.1 均衡過程
CIR中使用迭代算法避免了并行大向量和大矩陣的運算,而是分步運算。所以對輸入信號進行均衡,首先要進行并串變換,但是不需要變成真正的串行信號。當Q=2時,實際上對需要均衡的輸入信號Y(i)每次取出5個數據,用yk表示,暫且將這樣的變換叫作分組并串變換(P/GS),然后均衡矩陣ek與yk分組完成乘法運算得到一個zk,zk是一個數據不是向量,最后進行串并變換就得到均衡后的信號向量Z(i)。整個均衡的過程如圖5所示。
2.2.2 仿真結果
實現該算法的重要一步是所設計的乘加器可以正常使用,并且實時性好。對其進行仿真如圖6所示,可以發現當clk發生上升沿跳變時進行計算,圖中信號(a,b)表示輸入的數據信號;fcl表示相乘的結果;c表示進行乘加以后的運算結果,其計算準確,基本上沒有延遲。
實現該算法的重要一步是所設計的乘加器可以正常使用,并且實時性好。對其進行仿真如圖6所示,可以發現當clk發生上升沿跳變時進行計算,圖中信號(a,b)表示輸入的數據信號;fcl表示相乘的結果;c表示進行乘加以后的運算結果,其計算準確,基本上沒有延遲。

ISE中設計的傳輸模塊實現波特率為19 200 b/s的串口通信控制器,把數據通過RS 232完成FPGA與PC機的雙向通信。把均衡后的信號Z(i)傳回Matlab中,采用QPSK的星座圖進行分析,選擇子載波的數目N=128,循環前綴CP的長度為8,并且在認為信噪比被準確估計的情況下均衡的結果,如圖7所示。

由此星座圖可以看出,在均衡前接收到的信號因為多普勒頻移和噪聲的影響,偏離星座點向周圍發散,使用FPGA中均衡以后傳回的數據基本沒有發散現象。
3 結語
在ISE軟件平臺上使用Verilog語言實現了一種基于時變OFDM系統的低復雜度MMSE均衡器算法。在Xilinx公司Virtex-2實驗板(XC2V930芯片)上對其進行驗證,基本達到該算法在Matlab上仿真的均衡效果。但是由于浮點數計算量太大,選用定點數對其進行截取,還是有一定的局限性,在進行大量數據的運算中還是會有些數據不太準確,造成整體的誤碼率效果不是太好,故還需要進一步改進算法和FPGA的實現方法,以期達到更好的均衡效果。
3 結語
在ISE軟件平臺上使用Verilog語言實現了一種基于時變OFDM系統的低復雜度MMSE均衡器算法。在Xilinx公司Virtex-2實驗板(XC2V930芯片)上對其進行驗證,基本達到該算法在Matlab上仿真的均衡效果。但是由于浮點數計算量太大,選用定點數對其進行截取,還是有一定的局限性,在進行大量數據的運算中還是會有些數據不太準確,造成整體的誤碼率效果不是太好,故還需要進一步改進算法和FPGA的實現方法,以期達到更好的均衡效果。
此內容為AET網站原創,未經授權禁止轉載。