
摘 要: 以藏文" title="藏文">藏文音節作為輸入的基本單位,建立了音節與詞的編碼模型" title="編碼模型">編碼模型以及音節輸入、詞匯輸入和聯想輸入的模型并實現了藏文輸入方案。試驗結果表明,該方案科學、合理。輸入方法簡單、方便、快速。
關鍵詞: 藏文輸入 編碼模型 輸入系統模型
藏文輸入是藏文信息處理的一個重要內容。目前藏文輸入法主要有基字輸入法、拉丁輸入法和區位碼輸入法[1]。基字輸入法類似于拼寫輸入法[2],國外的Wylie[3]輸入法即為拉丁輸入法。基字輸入法和拼寫輸入法都是將字丁拆分成藏文字母,然后規定編碼順序,或者按照藏文書寫規則依次輸入。Wylie輸入法是鍵入字丁的拉丁轉寫,從而轉換為藏文字丁。總之,這幾種輸入法都是以藏文字丁為編碼單位輸入的。根據字丁的疊加層數,有不等的擊鍵次數:基字字丁需2鍵;疊字(含元音)字丁擊鍵次數比層數少1;無元音的3層疊字則需4鍵。參考文獻[4]實現了一種藏文詞組輸入方案,其基本特點是按照單音節詞、雙音節詞、三音節詞、四音節詞和多音節詞分別以每個詞各音節的基字與后置字編碼,實現藏文詞輸入。本文建立以音節為基本輸入單位的輸入模型、詞匯輸入模型及其相應的聯想輸入,從理論和實現的角度解決藏文的快速輸入問題。
2 藏文輸入法編碼方案模型
2.1 以音節為輸入單位的可行性及其編碼模型的建立
藏文音節結構的兩種形式如圖1所示。一個音節有7個成分,1、2、3、4、5、6、7分別為基字、上加字、下加字、前加字、后加字、又后加字和元音位置。除基字外,其它任何成分少一個或幾個,只要符合音節規則,都是合法音節。從左到右形成4個縱向單位,除第二個縱向單位外,其他三個部分都不缺或少一個、兩個、三個和四個,則分別形成四字、三字、雙字和單字音節。詞由一個或多個音節構成,音節之間用音節點分隔。

目前在中文Windows環境下處理藏文,音節的每一個縱向單位即字丁占一個漢字位置。
首先建立藏文音節編碼方案的模型,表示以音節為單位的輸入方案的可行性。根據參考文獻[5]、[6]的啟發并分析藏文的特點,定義了5個集合:(1)T={t:t是藏文音節}是規范藏文音節集。藏文有嚴格的音節拼寫規則,規范音節是本方案必須獲得的一個統計數據,根據已經統計的數據[7][8],集合T含有的元素個數約12 000左右。以此集為基礎建立如下各集。(2)W={![]() 為一個詞包含的音節數,w是詞}為藏文詞集。(3)C={c:c是鍵盤字符}是編碼字符集。C可以是小寫26個英文字母、大寫英文字母、10個數字0~9以及鍵盤上的其他字符。(4)S={s:s=C1C2……Cm,其中Ck∈C,k=1,2,……n是英文字母數目}是藏文數字、符號、音節、梵文代碼集。每個代碼s都是一個或若干編碼字符。因為S是T對應的編碼集,而不同音節有相同的代碼現象,如對三字音節:
為一個詞包含的音節數,w是詞}為藏文詞集。(3)C={c:c是鍵盤字符}是編碼字符集。C可以是小寫26個英文字母、大寫英文字母、10個數字0~9以及鍵盤上的其他字符。(4)S={s:s=C1C2……Cm,其中Ck∈C,k=1,2,……n是英文字母數目}是藏文數字、符號、音節、梵文代碼集。每個代碼s都是一個或若干編碼字符。因為S是T對應的編碼集,而不同音節有相同的代碼現象,如對三字音節: 和雙字音節:
和雙字音節: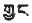 的編碼就可能一樣,因為前一個音節中的第二個字母在第二個音節中是下加字(變形顯示),所以S集的元素個數小于T集,即|S|≤|T|。(5)L={==∈S,k=1,2,……m},m為詞li包含的音節數,li為詞的代碼串,
的編碼就可能一樣,因為前一個音節中的第二個字母在第二個音節中是下加字(變形顯示),所以S集的元素個數小于T集,即|S|≤|T|。(5)L={==∈S,k=1,2,……m},m為詞li包含的音節數,li為詞的代碼串,![]() 對應的代碼}。
對應的代碼}。
設規范藏文音節集T中所有子集(即冪集)表示為2T,S為T的代碼集。根據以上集合可建立如下音節編碼模型。
定義1 若g是S到2T的一個映射:g:S→2T,即s→g(s)且對任意的音節t∈T,g-1({t}≠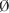 ,則稱g為一種音節編碼方案。若存在s∈S,使得|g(s)|>1,則稱g為有重碼的音節編碼方案,這時,g(s)中的藏文音節的代碼都是s。若對于每個s∈S,總有|g(s)|=1,則g為無重碼的音節編碼。
,則稱g為一種音節編碼方案。若存在s∈S,使得|g(s)|>1,則稱g為有重碼的音節編碼方案,這時,g(s)中的藏文音節的代碼都是s。若對于每個s∈S,總有|g(s)|=1,則g為無重碼的音節編碼。
若g為無重碼的藏文音節編碼,則g是S到T的單滿射。這樣s和g(s)一一對應。實際上g不是一個單滿射,這在實際設計中是允許的。反之,任何一個規范音節,根據某種編碼方式都有編碼。如果把以音節為單位的藏文信息輸入過程看成通過輸入音節代碼得到藏文音節的過程,則有:
定義2 音節的代碼轉換為藏文的模型可以表示為:ti=g2°g1(si),其中gi(si)表示取得代碼Si的重碼音節集,g2表示重碼音節中的選擇處理,最后得到規范音節集中的藏文音節ti。
因為|gi(si)|≥1,即代碼Si所對應的音節至少有一個,當|gi(si)|>1時,即代碼Si對應多個音節,而g2表示從這多個音節中選取一個。可以由輸入者完成,也可以由計算機自動完成。如果自動完成,則必須通過音節的轉移概率或藏文語言知識的應用。
因為信息輸入是一個狀態轉移過程,如前面定義的藏文音節集、代碼集、代碼字符集,可以建立如下音節輸入模型:
定義3 代數系統<2T,S,g,,T>稱為以音節為單位的藏文輸入處理系統模型,其2T是藏文音節集T的所有子集(即T的冪集),稱為該代數系統的狀態集;空集表示初始狀態;T為終結狀態集;g稱為狀態轉移函數,是2T×S到T的一個映射:g:2T×S→2T。若用q表示狀態,則模型:(q,s) g(q,s)=q∪{![]() g(i)(g1(s))}就表明在狀態q下,如果再輸入代碼s,則得到以s為代碼的重碼音節集g1(s)。n=|g1(s)|是g1(s)中所含元素的個數。
g(i)(g1(s))}就表明在狀態q下,如果再輸入代碼s,則得到以s為代碼的重碼音節集g1(s)。n=|g1(s)|是g1(s)中所含元素的個數。![]() g(i)(g1(s))表示從g1(s)的元素集合{g(1)(g1(s)),g(2)(g1(s)),……g(n)(g1(s))}中取定一個。
g(i)(g1(s))表示從g1(s)的元素集合{g(1)(g1(s)),g(2)(g1(s)),……g(n)(g1(s))}中取定一個。
因為藏文的詞都是由若干個音節組成的,所以當音節的代碼集是S時,若用f鍵符表示空格,則S+f表示音節代碼加空格符的集合。于是詞的代碼集為:
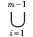 (S+f)i-1S=S∪(S+f)S∪……∪+(S+f)m-1S=S∪(S+f)×S∪……∪(S+f)×(S+f)×……(S+f)×S的子集,其中m=max{|k|:|k|是詞包含的音節個數},于是有:
(S+f)i-1S=S∪(S+f)S∪……∪+(S+f)m-1S=S∪(S+f)×S∪……∪(S+f)×(S+f)×……(S+f)×S的子集,其中m=max{|k|:|k|是詞包含的音節個數},于是有:
定義4 若g是(S+f)i-1S到詞集W的所有子集2W的一個滿射,則g為一藏文詞輸入編碼方案。對于該編碼方案g,若有w∈W,則g(-1)({w})=是不允許的;若有s∈(S+f)i-1S,則可以有g(s)=。
有了藏文詞的編碼方案,即可以得到詞輸入系統的模型:
定義5 一個詞輸入系統的模型是一個5元代數系統<2W,L,g,,W>,其含義如下:
2W是藏文詞集W的所有子集,是該代數系統的狀態集;L=(S+f)i-1S是詞的代碼集;空集表示一個詞也沒有輸入時的初始狀態;W稱為系統的終結狀態集;g稱為狀態轉移函數,是2W×L到2W的一個映射:g:2W×L→2W,(q,l)|→g(q,l)=q∪{![]() g(i)(g1(l))}。其中g1是一個詞編碼方案,它是L到2W的一個映射;g1(l)是代碼為l的重碼詞集合;g(i)是{g1(l)|l∈L}到W的一個映射。
g(i)(g1(l))}。其中g1是一個詞編碼方案,它是L到2W的一個映射;g1(l)是代碼為l的重碼詞集合;g(i)是{g1(l)|l∈L}到W的一個映射。![]() g(i)(g1(l))表示從集{g(1)(g1(l)),g(2)(g1(l)),g(3)(g1(l)),……g(n)(g1(l))}中選取一個,它是詞集W中的一個確定元素。
g(i)(g1(l))表示從集{g(1)(g1(l)),g(2)(g1(l)),g(3)(g1(l)),……g(n)(g1(l))}中選取一個,它是詞集W中的一個確定元素。
從上面的" title="面的">面的模型可以發現,如果以s為代碼的音節集![]() g(i)(g1(s))和以l為代碼的詞集
g(i)(g1(s))和以l為代碼的詞集![]() g(i)(g1(l))的個數很多,在實際輸入法應用中可選擇兩種方法:一是手工鍵選,即在輸入法候選窗口通過翻頁選擇。如果每次都要不斷翻頁選擇,不僅打斷人的思維,也不能有效提高輸入速度。二是通過語言知識的統計和應用自動選擇。鑒于藏文語言應用研究的現狀,通過兩種辦法來解決這個問題:(1)詞頻。通過靜態的詞頻排序盡量減少翻頁,達到快速輸入的目的。(2)智能記憶。將靜態統計和輸入時的動態統計情況相結合,通過記憶,不斷調整靜態統計的結果,適應輸入者的動態需要,減少翻頁鍵選。
g(i)(g1(l))的個數很多,在實際輸入法應用中可選擇兩種方法:一是手工鍵選,即在輸入法候選窗口通過翻頁選擇。如果每次都要不斷翻頁選擇,不僅打斷人的思維,也不能有效提高輸入速度。二是通過語言知識的統計和應用自動選擇。鑒于藏文語言應用研究的現狀,通過兩種辦法來解決這個問題:(1)詞頻。通過靜態的詞頻排序盡量減少翻頁,達到快速輸入的目的。(2)智能記憶。將靜態統計和輸入時的動態統計情況相結合,通過記憶,不斷調整靜態統計的結果,適應輸入者的動態需要,減少翻頁鍵選。
2.2 音節和詞的聯想輸入
在設計聯想輸入時分為以下兩個層次。
(1)音節輸入過程的聯想
音節t可以用代碼s表示,而s=C1C2……Ck,Ci∈C,i=1,2,……k,C1C2……Ck是對一個音節的編碼。一個音節最多由四個縱向單位,七個成分組成,最少只有一個輔音字母,所以音節的代碼串是不定長碼。于是,音節的聯想可以有多種方式,如由前加字聯想可能的基字、上加字、下加字、后加字和又后加字;或由基字聯想可能的其他成分而組合成的規范音節。隨著代碼序列s的輸入,每個Ci的輸入既和前面字母的結合有確定性,又對后面有聯想結果,以供選擇,直到音節代碼輸入結束。
(2)詞輸入過程的聯想
詞的代碼由若干個音節的代碼組成,輸入第一個" title="第一個">第一個音節時的聯想是音節的聯想,輸入第二個及以后的音節時則進入詞的聯想。詞的聯想是根據前面的n個音節聯想的,當輸入第n+1個音節的第一個代碼時,聯想下一個可能音節的詞,依次類推。
3 實驗結果與分析
前面用藏文的拉丁轉寫作為輸入代碼,實現了以音節為輸入單位的藏文輸入法。圖2為輸入窗口和選擇窗口,實現一個音節的輸入和聯想過程。當輸入y時,聯想出以 為基字的所有可能的音節;當輸入yo時,聯想出以
為基字的所有可能的音節;當輸入yo時,聯想出以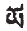 基字位置的所有音節;當輸入yos時,聯想出以為基字、后加字拉丁轉寫為sa的藏文音節(此時有惟一一項)。
基字位置的所有音節;當輸入yos時,聯想出以為基字、后加字拉丁轉寫為sa的藏文音節(此時有惟一一項)。
圖3為詞的聯想輸入過程。輸入一個6音節的詞(其拉丁轉寫為:kun brtags kyi ma rig pa),候選窗口序號1所在的詞即為要輸入的詞。如左側的輸入窗口和候選窗口所示,當輸入第二個音節的拉丁轉寫首字母時,聯想出所有第一個音節為kun,第二個音節的前加字、基字為ba的藏文詞。隨著輸入的繼續,候選窗口列表在已確定的前面幾個音節的前提下,聯想后面的音節。


上述輸入方案以實現為目標,以實用為目的。在本方案的基礎上,設計和實現了一個藏文輸入系統。實驗表明該輸入方案科學、合理。
參考文獻
1 彭壽全,黃 可.漢字信息處理.成都:電子科技大學出版社,1994:336~360
2 柔 特,才智杰.班智達藏文詞組輸入法的設計與實現.少數民族語言信息技術研究進展——中國少數民族語言信息技術與語言資源庫建設學術研討會論文集,2004:228
3 谷文祥.關于計算機漢字信息輸入處理的一個新模型.計算機研究與發展,1995;(7):61~65
4 錢培德.計算機漢字I/O處理的數學模型.中文信息學報,1992;(2):46~51
5 王維蘭.現代藏文語言單位頻率和頻級關系的統計分析.科學技術與工程,2004;(5):413~417
6 王維蘭,陳萬軍.藏文字丁、音節頻率及其信息熵.術語標準化與信息技術,2004;(2):27~31