
??? 摘 要: 針對cdma2000-1X網絡中無線信號的特點和無源定位的需要,通過將N階多項式平滑擬合及加權修正的思想融合到遺傳算法" title="遺傳算法">遺傳算法中,提出了一種改進的遺傳算法來消除NLOS誤差和多徑" title="多徑">多徑傳播誤差對載干比的影響。不僅避免了遺傳算法“早熟”的發生,而且還可以根據實際情況靈活改變搜索精度,使算法搜索達到全局最優,從而實現精確估計信號到達方位的目的。經過場外試驗和MATLAB仿真驗證該算法可以達到比較好的效果。
??? 關鍵詞: 無源定位? 信號到達時延? 信號到達方位? 非視距誤差? 載干比
?
??? 由于美國聯邦通訊委員會在E-911標準中要求無線通信網絡必須能夠提供基于移動用戶的位置估計的功能,無線定位越來越受到各國公司及研究人員的關注[1]。利用各種通信標準中現有的資源,在復雜的無線通信環境中提高定位的精度是當前研究的重點。在CDMA系統中為實現符合E-911精度要求的定位,有兩個問題必須解決:一是怎樣減小基站與用戶間的非視距NLOS(Non-Line-of Sight)誤差、多徑傳播誤差對定位精度" title="定位精度">定位精度的影響;二是由于CDMA蜂窩系統是一個功率控制系統,當用戶發射信號只能被一個基站接收時,怎樣實現用戶定位,并能使定位精度盡可能得到提高[2-3]。在此情況下,TOA/AOA(Time of Arrival/Angle of Arrival)是最為有效的方法。該方法中,信號到達角的精確估計是實現高精度定位的必要條件。精確的信號到達角估計必須借助于基站通過通信網絡來實現。但在無源定位系統中,被定位對象和基站并不參與定位過程,信號到達角是根據定位設備自身所接收的信息來估計得到的。由于受天線分辨率等因素的影響,往往并不能從測量值中精確估計出信號到達角,而是獲得信號到達方位角的范圍,即信號到達方位OOA(Orientation of Arrival)。若在定位的后期處理部分加上適當的優化算法也能實現精確定位。
??? 在天線分辨率確定的前提下,信號到達方位估計得越準確,最后的定位精度也就會越高。而NLOS誤差和多徑傳播誤差是信號到達方位準確估計的主要干擾因素。這些因素的存在不僅會使信號到達方位的判斷產生偏差,甚至會產生錯誤判斷,所以要提高定位精度就必須消除這些因素的影響。
??? 遺傳算法是近年來智能算法領域提出的解決工程優化問題的一種有效方法,可以用來消除NLOS誤差和多徑傳播誤差。但傳統的遺傳算法并不能有效地消除這些誤差的影響,需要對傳統的遺傳算法進行改進,以便達到比較理想的效果。
??? 用N階多項式對一段時間內的測量值進行平滑擬合,根據擬合值與測量值之間的偏差,對平滑值進行加權修正,可以得到近似LOS環境下的測量值[4],但是由于受定位時間要求的限制,天線在每個角度的測量值不能太多,并且算法的搜索精度也不能根據實際情況靈活地改變,所以僅采用該方法消除非視距誤差和多徑傳播誤差的影響并不能達到理想的效果。
??? 本文提出了把上述兩種方法融合到一起使用的改進遺傳算法,經過場外試驗和MATLAB仿真驗證,改進后的算法能夠有效地消除NLOS誤差和多徑傳播誤差對測量值的影響,實現準確估計信號到達方位的目的。
1 定位方法及信號到達方位的判斷
?? 在cdma2000-1x無源定位系統中,由于定位的過程是在被定位對象與基站正常通信的基礎上通過定位設備來完成的,不需要被定位對象和基站參與定位過程。本文采用的方法如圖1所示。?
?????????????????????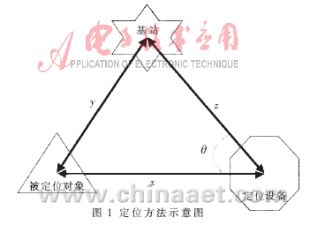
??? 當基站與被定位對象通信時,定位設備可以獲取信號從基站經被定位對象到達定位設備所需的時延和。由于定位設備和基站的位置是確定的,并且可以通過定位設備利用GPS測量獲得。由圖1可知,通過定位設備,可得到x+y和z的值,由余弦定理可知:只要得到角度?茲的值,就可以求出x的值。由于基站和定位設備位置是可以直接測得的,若能準確估計出信號從被定位對象到定位設備的到達角,就可以得到被定位對象的具體位置。
??? 在上述定位過程中,OOA信息的準確獲得是實現精確定位的必要前提,而OOA信息是通過對定位設備測得的載波干擾比即載干比CIR(Carrier to Interference Ratio)進行分析獲得的。
??? 在LOS環境下,由于天線有主瓣和旁瓣,當天線正對著信號到達方位時,主瓣也正對信號到達方位,則測量所得到的信號的載干比的均值比較大,而方差則普遍比較小,即載干比的分布比較集中;而當天線偏離信號到達方位時,主瓣也偏離信號到達方位,則測量得到的信號載干比的均值比較小,而方差則普遍較大,即載干比的分布比較分散。上述特點在多次場外試驗中也得到了充分驗證。針對以上特點,可以把載干比的均值和方差兩個量作為判斷標準,進而判斷天線所對方向與信號的到達方位的偏離程度。由于載干比的值是負值(單位dB),所以可以利用載干比的均值和方差的乘積作為判斷指標。若兩者的乘積值越大,則表明定位設備的天線所對的方向就越接近信號到達方位;反之,就越偏離信號的到達方位。
??? 在NLOS環境中,定位設備在各個角度接收到的信號載干比受NLOS誤差和多徑傳播誤差的影響比較大,甚至會被這些干擾所淹沒,所以直接利用測量所得的載干比的均值和方差進行判斷就很難準確地估計天線所對的方向與信號到達方位的偏離程度,甚至會帶來很大的偏差。要想使定位設備在各種通信環境中均能實現精確定位,就必須采用一些優化算法消除NLOS誤差和多徑傳播誤差的影響。
2 傳統遺傳算法優缺點分析
??? 遺傳算法(Genetic Algorithm) 是一類借鑒生物界進化規律演化而來的隨機搜索方法,是模擬達爾文的遺傳選擇和自然淘汰的生物進化過程的計算模型。作為一種新的全局最優化搜索算法,它以其簡單通用、魯棒性強、適于并行處理以及高效、實用等顯著特點,在各個領域得到廣泛的應用[5]。
??? 由于該算法搜索過程不直接作用在變量上,而是對參數集進行個體編碼,所以采用合適的編碼方法可以靈活改變搜索精度。采用概率化的尋優方法,能自動獲取和指導優化的搜索空間,自適應地調整搜索方向,不需要確定的規則,并且算法是從串集開始搜索,覆蓋面積大,利于全局擇優。即使算法的初始串集本身帶有大量與最優解甚遠的信息,通過選擇、交叉、變異操作也能迅速排除與最優解相差極大的串,因此該算法是一個強烈的濾波過程,具有很強的容錯能力[5]。正是由于遺傳算法的上述優點,使得遺傳算法可以用來消除非視距誤差對信號載干比的影響。
??? 但傳統的遺傳算法也有其致命的缺點,如“早熟”和局部搜索" title="局部搜索">局部搜索能力差。“早熟”容易導致搜索陷入局部最優解,而局部搜索能力差可能導致搜索后期效率不高,甚至陷入隨機搜索的誤區。初始化群體的選擇和編碼方法的選擇也會給遺傳算法帶來很大的影響。因此為了充分發揮遺傳算法的性能,就必須對遺傳算法進行改進,以達到發揮其優越性而克服其缺陷的目的。
3 N階多項式平滑及加權修正算法
??? 該方法的主要思想是:首先對天線在每個角度下的測量值利用N階多項式進行平滑擬合(N階多項式的系數是根據測量值用泰勒級數來獲得的,采用的最優化準則是最小二乘法);然后對平滑曲線進行采樣,根據平滑曲線采樣點與該點所在曲線段的均值的偏差,進行加權修正平滑曲線。加權系數的選取遵循偏差絕對值大加權系數小,偏差絕對值小加權系數大的原則。
??? 采用該方法可以把NLOS環境下測量得到的測量值通過擬合、平滑加權修正得到近似LOS環境下的測量值,達到消除NLOS誤差和多徑傳播誤差的效果,但是該方法也受測量值數量的限制,即在測量值比較少的情況下,采用該方法效果也并不理想[3]。該方法的修正是在平滑值基礎上進行加權修正的,加權系數的選擇對算法的性能影響也比較大。加權系數的選取不能太大,否則會引來額外的誤差;如果加權系數選取的過小,則不能達到完全消除NLOS誤差和多徑傳播誤差的目的,并且該方法的搜索精度不能根據實際情況做適當的改變。因此在測量值受誤差影響比較嚴重或者影響不斷變化的情況下并不能有效消除NLOS誤差和多徑傳播誤差的影響。
4 改進遺傳算法
??? 改進遺傳算法是把N階多項式平滑及加權修正法與遺傳算法融合一起使用。該算法主要是利用N階多項式擬合加權修正的思想來彌補遺傳算法的“早熟”和局部搜索能力差的缺陷;利用遺傳算法全局搜索能力強和容錯能力強及搜索精度可以靈活改變的優勢來彌補加權系數選擇的局限對N階多項式擬合加權修正算法性能的影響,并且有效降低了測量值數量對算法性能的影響,使改進算法的性能在實際應用中得以充分發揮。
??? 改進遺傳算法如下:
??? (1)在初始化群體選擇時,把N階多項式平滑、擬合的方法融入其中,實現初始化群體在搜索空間的均勻分布,從而有效避免早熟現象的發生,減小搜索陷入局部最優解得可能性,并且可以降低測量值數量對算法性能的影響。
??? 實現思路:在測量值的基礎上利用最小二乘法和泰勒級數的方法對測量值進行N階多項式平滑、擬合,形成擬合曲線;然后利用均勻采樣的方法對曲線進行采樣,把采樣所得的值作為測量值的有效補充。假設在每個角度下的測量值個數為N,則經過擬合后的曲線可以分為N-1段。若在改進遺傳算法中選擇的初始化群體中元素的個數為W=a(N-1),則在選擇遺傳算法的初始群體時,在平滑曲線的每一段隨機選取a個值作為初始化群體的元素,通過上述方法就實現了初始化群體在搜索空間的均勻分布,可以有效避免搜索陷入局部最優的發生。
??? (2)在進行編碼之前,先對采樣點進行等級劃分,把采樣值均勻劃分為2 000個等級,等級劃分規則如下:令最小的采樣值為Mmin,其等級值Smin=1,最大的采樣值為Mmax,其等級值Smax=2001,等級間隔為scale。則:?
??? 
??? 假設采樣值M的等級值為SM,則有:
??? 
??? 然后把初始化群體中的元素也轉換成相應的等級值,參與遺傳算法的編碼。
??? (3)為了使算法能隨通信環境的改變而靈活改變搜索精度,在對初始化群體的元素等級進行編碼時,采用格雷碼" title="格雷碼">格雷碼進行編碼。這樣,在通信環境惡劣的情況下,就可以自動增大搜索精度;而在通信環境理想時,就可以自動減小搜索精度,從而使算法能更有效地消除NLOS誤差和多徑傳播誤差。
??? 在本改進算法中,采用格雷碼進行個體編碼,該碼是由自然二進制碼轉換而來,其轉換方法如下:假設自然二進制編碼為B=bmbm-1…b2b1,其對應的格雷碼的轉換公式為:
??? 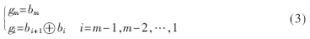
??? 格雷碼的特點是連續的兩個整數所對應的編碼值之間只有一個碼位是不相同的,任意兩個整數的差是這兩個整數所對應的格雷碼之間的海明距離,這使得在遺傳算法中的一次交叉、變異操作也僅使其對應的參數發生微小的變化,有助于提高遺傳算法的局部搜索能力,也便于交叉、變異操作,并且可以根據測量值的實際情況對搜索精度做靈活的改變[5]。
??? (4)為了保持樣本的多樣性,本改進算法采用單點交叉的方法,交叉概率為0.4。這樣既可以滿足產生新個體的要求,又不會破壞個體的適應度,使算法很容易地搜索到最優解附近,具有很強的全局搜索能力。
??? 在本文的改進算法中,選取的變異概率為0.001,變異方法是非均勻變異,它相當于整個解向量在解空間作了一個輕微的變動,可以重點搜索原個體附近的微小區域,更有利于搜索到最優解,使算法只需花費很小的代價就可以從最優解附近搜索到達最優解。
??? (5)在適應函數選取前把交叉前后的串先進行解碼,把等級值轉換為載干比值。
實現思路如下:先把格雷碼轉換為自然二進制碼,假設格雷碼為:G=gmgm-1…g2g1,則轉化為自然二進制的方法為:
??? 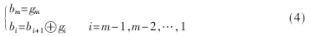
??? 再把解碼后的等級值轉換成載干比值,轉換方法如下:假設采樣點N的等級值為SN,則采樣點N的初始值為:
???  ?
?
??? (6)在適應函數選取及復制操作中,把交叉、變異操作前的初始化群體的值和操作后的值按照它們與所在曲線段的均值的偏差的大小進行加權疊加,產生新的初始化群體元素。
??? 實現思路為:①先找出搜索點所在曲線段,然后求出該曲線段的載干比的平均值;②計算搜索點在交叉、變異操作前的載干比值與所在曲線段的載干比均值的標準偏差,令為f1;③計算搜索點在交叉、變異操作后的載干比值與所在曲線段的載干比的平均值的標準偏差,令為f2;④若設搜索點的載干比為CIR1,交叉變異操作后的載干比為CIR2,選擇復制后的載干比為new_CIR;令:a1=f1/(f1+f2), a2=f2/(f1+f2)則:?
??? 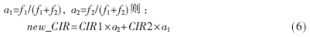
??? 在原來初始化群體元素的基礎上,該方法利用交叉、變異操作,對元素附近區域進行搜索,然后根據偏差的大小進行加權修正,充分利用各個曲線段內相鄰點之間的相關性,可以更為有效地消除NLOS和多徑傳播的影響。
??? 為了減小算法搜索隨機性對優化結果的影響,本文采用多次迭代、求平均值的方法。
5 仿真結果及性能分析
??? NLOS和多徑傳播是載干比測量值產生偏差的主要因素,它既可使載干比的測量值產生正向偏差,也可使載干比測量值產生負向偏差,并且偏差的統計特性也是未知的。
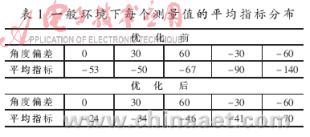
??? 為了充分驗證算法在各種通信環境下的性能,本文分兩部分進行驗證:第一部分是對一般的通信環境(受NLOS誤差和多徑傳播誤差影響比較小)測量結果進行驗證,第二部分是對通信環境比較復雜情況下(受NLOS誤差和多徑傳播誤差影響比較大且不斷變化)測量結果進行驗證。由于對信號達到方位信息的判斷是通過載干比的均值和方差兩個指標來衡量的,所以在驗證算法性能時,主要也是從優化前后載干比的均值和方差的變化情況來綜合衡量算法的性能。
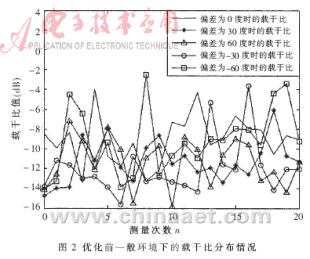
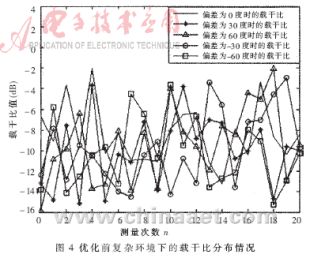
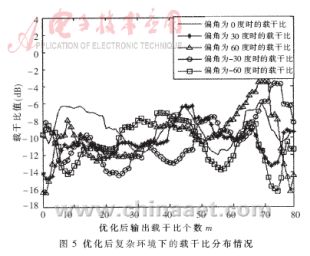
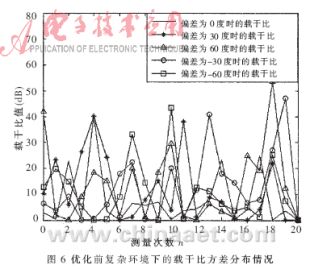
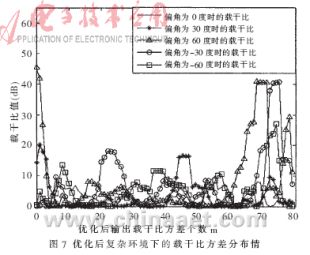
??? 本文采用MATLAB做仿真驗證。仿真結果如圖2~圖7及表1和表2所示。在圖2、4、6中的橫坐標表示在每個角度下獲得的測量值的個數,在圖3、5、7中橫坐標表示優化后輸出的載干比個數;在圖2 、3、4、5中縱坐標表示載干比值(單位dB),在圖6、7中縱坐標表示載干比方差。
????????????????????????
?????????????????????????? 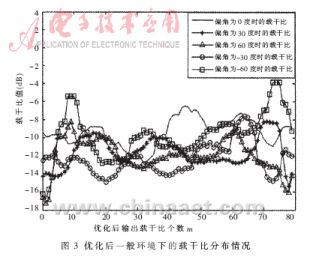
??? 其中,表1和表2中的角度偏差是天線所對方向與信號到達方位的偏差,指標是判斷角度偏差大小的衡量指標,即載干比的均值與方差的乘積。平均指標是天線在每個角度下所有測量值產生的指標的總和與測量值個數的比值。從圖2~3分析可知優化后載干比的均值變化不大,而分布相對比較集中,既方差普遍變小,并且各個角度之間的方差區別更加明顯。從表1可以看出,優化后每個測量值的平均指標有所提高,并且區分更為明顯。
????????????????????????????? 
?
????????????????????????????? 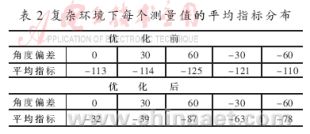
??? 從圖4~圖7及表2分析可知優化后載干比的均值變化不大,但方差變化普遍有所減小,并且比較明顯。在優化前由于受干擾因素的影響比較大,利用載干比的均值與方差的乘積作為指標來判斷天線所對角度與實際信號到達方位的偏離程度是非常困難的,因為從圖中可以看到載干比的分布都比較分散,并且各個角度下的差別不大,在干擾因素比較大的情況下,甚至還會出現偏離程度比較大,但測量值所反應出的判斷指標反而比較大,導致嚴重的錯誤判斷(如天線在-60°時的情況)。而經過優化處理后,載干比的分布比較集中,并且方差普遍降到一個較小的范圍內,從表2中反應的指標分析,各個角度偏差的判斷指標也都得到了提高,并且差別也比較明顯。即使是在干擾因素影響比較大的情況下,也能避免偏離程度比較大而測量值所反應的判斷指標也比較大的情況發生,有效抑制錯誤判斷的發生,從而實現了信號到達方位的精確估計。
???????????????????????????? 
????????????????????????????? 
?????????????????????????????? 
??????????????????????????????? 
????場外試驗和仿真實驗表明,該算法不僅能避免遺傳算法“早熟”現象的發生,而且克服了N階多項式擬合及加權修正的方法不能根據實際情況靈活調整搜索精度的缺陷,并且有效抑制了測量值的數量對誤差消除程度的影響,可以有效消除NLOS誤差和多徑傳播誤差對測量值的影響,避免錯誤判斷的發生,實現精確估計信號到達方位的目的。
參考文獻
[1] 范平志,鄧平,劉林.蜂窩網無線定位[M].北京:電子工業出版社,2002.
[2] CAFFERY J. Wireless location in CDMA celluar radio?systems [M].Boston:Kluwer Academic Publishers,2000.
[3] CAFFERY J. STUBER L. Subecriber location in CDMA?celluar networks [J]. IEEE Trans,on Vehicular Technology,1998,47(2):406-415.
[4] WYLIE M P, HOLTZMAN J. The non-line-of sight?problem in mobile location estimate [A].IEEE International ?conference on universal person communication Cambridge,Massachusetts,USA, 1996: 827-831.
[5] 周明,孫樹棟.遺傳算法原理及應用[M].北京:國防工業出版社,1999.
?