
摘 要: 家電語音控制" title="家電語音控制">家電語音控制系統在復雜的背景環境下,由于識別率顯著下降而導致關鍵詞檢出率偏低。介紹了利用孤立詞、連接詞" title="連接詞">連接詞以及連續語音識別引擎" title="識別引擎">識別引擎構造的多識別引擎的識別器,該識別器允許用戶自由選擇語音輸入方式,擴大了關鍵詞的檢出范圍,從而達到提高關鍵詞檢出率的目的。同時給出了家電語音控制系統" title="控制系統">控制系統的整體結構,分析了影響系統性能的關鍵因素,并且給出了相應的解決方案。
關鍵詞: 語音識別" title="語音識別">語音識別 家電語音控制 語音確認 關鍵詞檢出
近年來,隨著語音識別與確認技術的逐漸成熟,基于語音識別技術的對話控制系統受到了越來越多的關注。現有的語音技術雖然在實驗室環境中取得了較好的識別效果,但是一旦由于環境或者說話人的客觀原因使得語音信號變差時,就會導致系統檢出率急劇下降,從而使得語音控制系統的性能變差甚至不能正常工作。
針對殘疾人行動不便的問題,在日本富士通公司的資助下開發了一套殘疾人利用語音進行家電控制的系統。本系統的用戶主要是康復中心的特殊用戶,由于身體長期癱瘓或者其它原因,他們不僅行動不便,而且語言交流能力也有很大程度的下降,尤其是發音不夠清晰準確,僅僅用傳統的語音識別器很難滿足控制系統實際應用的需要。因此,提出了綜合利用孤立詞識別器、連接詞識別器以及連續語音識別器構建一個基于多識別引擎的識別器的方法,使得關鍵詞被正確檢出的可能性大大增加,在允許用戶自由使用孤立或者連續語音交流的同時,還最大限度地利用不同識別引擎的優點,改善了家電語音控制系統的性能。
另外,還分析了語音控制系統中確認、模型自適應以及對話控制策略等關鍵技術,并且給出了相應的解決方案,從而給出了家電語音控制系統的完整結構,在電梯、輪椅、電視等設備的實際控制中取得了良好的效果。
1 家電語音控制系統的結構
家電語音控制系統包括軟件設計和硬件設計兩部分。本文主要討論軟件設計部分,其中包括:語音識別模塊、語音確認模塊、對話控制及硬件指令傳輸模塊以及模型自適應模塊。整個系統的流程是:首先,用戶的語音被送入語音識別模塊進行Viterbi解碼識別,得到相應的候選關鍵詞;然后,將候選關鍵詞送入語音確認模塊進行確認,從中檢出可能的關鍵詞,并給出相應的確認分值;再后,根據檢出的關鍵詞及其對應的確認分值產生相應的對話或者控制命令對硬件進行控制,同時利用已經確認的語音對識別器中的語音模型進行更新。圖1給出了家電語音控制系統的結構圖。
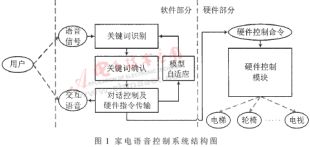
2 基于多識別引擎的識別器設計
2.1 傳統識別引擎簡介
根據待識別語音屬于單一用戶還是公眾進行分類,可以將其分為特定人識別以及非特定人識別。由于設計目標是針對特定用戶的,因此采用特定人識別器。如果根據輸入語音特點以及建模方法進行分類,當前的識別引擎主要分為孤立詞識別、連續語音識別以及連接詞識別等引擎。下面分別介紹幾種不同的識別引擎以及各自的優缺點。
2.1.1 孤立詞識別引擎
由于孤立詞識別引擎的輸入是孤立的詞匯,因此其識別范圍小,建模精確,識別率高,非特定人的孤立詞識別引擎的識別率可達95%左右,特定人的識別率甚至可達99%以上。但是孤立詞識別引擎要求用戶的輸入必須是一個個獨立的單詞,顯然對于連續的語音流無法處理。即使是獨立的單詞,如果由于用戶的習慣或者生理原因,在語音中含有一些語氣詞或者其它高能量的突發噪聲,將嚴重影響系統的識別率。
2.1.2 連續語音識別引擎
連續語音識別引擎是以音節或者音素為單位進行建模的,很好地解決了孤立詞識別中對輸入語音的限制,而且通過對常見的語氣詞以及噪聲的建模,也能夠解決由其引起的識別率下降的問題。但是連續語音的識別率很低,即使在實驗室環境下,其識別率最高也只能達90%左右。顯然連續語音識別引擎難以單獨用于家電語音控制系統。
2.1.3 連接詞識別引擎
連接詞識別引擎介于孤立詞識別引擎和連續語音識別引擎之間。它以孤立詞為模型,通過對孤立詞的拼接實現對連續語音流的識別。對于小型的語音識別系統來說,由于其詞表較小,因此建模方便,而且建模精度高,對關鍵詞的識別率接近于孤立詞識別引擎,很好地解決了孤立詞識別引擎無法解決的連續語音流問題。但是當輸入語音流包含過多的音節時,其識別率不可避免地會下降很多。
用戶在選擇識別引擎的時候,主要需要考慮的因素包括:識別率、實時響應速度、魯棒性、輸入語音限制、使用舒適性等。
2.2 基于多識別引擎的識別器設計
通過對識別引擎的分析以及對傳統識別引擎的介紹可以看到,無論單獨選擇哪種識別引擎,都不能夠完善地滿足實用的語音控制系統的要求,因此設計了一種多識別引擎的并行識別器,能夠獲得傳統識別器無法兼得的優點。圖2給出了基于多識別引擎的識別器結構圖。

2.2.1 基于多識別引擎的識別器工作原理
圖2中,識別引擎1為孤立詞識別引擎;識別引擎2為連接詞識別引擎;識別引擎3為連續語音識別引擎。識別器具體的工作流程如下:
(1)對輸入語音進行預處理,包括語音信號的切分以及噪聲去除等。語音信號的切分采用的是基于能量窗計算的切分算法[1],使得語音信號的端點更準確。
(2)根據輸入語音的物理長度以及其它物理特征預判輸入語音為孤立詞輸入還是連續語音輸入。如果語音信號較短,則采用識別引擎1、2進行識別;如果信號較長,則采用識別引擎2、3進行識別;如果不能確定是孤立語音還是連續語音,則同時采用三個識別引擎進行識別。
(3)對于不同的識別引擎,將得到的識別結果作為候選關鍵詞(如果識別結果不同則為多候選)送入確認模塊進行確認。
2.2.2 基于多識別引擎的識別器性能分析
由于基于多識別引擎的識別器至少同時啟動了兩個或者三個識別引擎,因此系統的響應時間不可避免地要受到影響。所以在語音建模時,采用參數共享的方式,從而降低了計算法復雜度,提高了系統響應速度。同時注意到,對于孤立語音來說,由于識別引擎1、2的識別速度很快,因此完全可以滿足實時響應的要求;對于連續語音來說,其識別時間主要耗費在識別引擎3上,這是不可避免的,系統引入的附加耗時很小,因此基本上不會因此而降低系統的響應速度。
而多識別引擎的識別器的建立,使得無論連續語音輸入還是孤立語音輸入,都能采用合適的識別引擎進行識別,從而在允許用戶自由交流的基礎上,保證了系統的識別率得到大幅度的提高。尤其是用戶在采用連續語音輸入系統不能正確識別時,可以降低要求,視其為孤立語音輸入,這樣一方面可以正確控制家電正常運行,另一方面通過自適應,不同識別引擎的模型都得到了更為精確的刻畫,逐漸提高了系統識別率,從而使得連續語音識別率也得到了提高。另外,在各種情況下都采用了連接詞識別引擎,主要是考慮到殘疾用戶的語音中經常附帶一些常見的突發噪聲以及語氣詞,因此通過對此進行獨立建模,能夠去除語音信號首尾的噪聲和語氣詞的影響,進一步提高識別器的魯棒性。
3 其它關鍵技術分析
在家電語音控制系統中,除了識別器的性能嚴重影響系統的運行性能以外,關鍵詞確認、對話控制策略以及識別器自適應也是至關重要的:關鍵詞確認的結果給出候選關鍵詞的置信度,因此直接影響了后續的對話控制模塊可能采取的動作——當置信度高時,接受該關鍵詞將其作為真正的關鍵詞并且發出相應的控制指令;當置信度較低時,拒絕該候選詞;當置信度處于中間水平時,產生相應的對話語音與用戶進一步進行交互,對可能要發生的動作進行確認。在實際應用中,自適應技術保證了通過長期的用戶和系統之間的交互,對識別器的模型進行修正,從而提高用戶的語音識別率。
基于多識別引擎的識別器給關鍵詞確認模塊提供了更多的候選關鍵詞,因此擴大了關鍵詞的檢出范圍,為進一步提高檢出率提供了條件;但是另一方面,更多的候選關鍵詞意味著錯誤的候選關鍵詞被接受的可能性也大大增加,系統的誤警率也會隨之上升。因此對于關鍵詞確認性能的依賴也會更大,所以提取出多種有效的確認特征,利用神經元網絡進行最終的置信度評價。這些確認特征包括:音素匹配得分特征、音素數匹配得分特征、似然得分特征、似然排位得分特征以及模型距離差累積得分特征。詳細的確認過程見參考文獻[2]。
在對話控制模塊中,由于不同的電器對應著不同的關鍵詞,因此通過記錄當前對話所處的狀態(應用某一個電器的狀態或者空閑狀態),給識別器提供相應于該狀態的關鍵詞表,大大縮小了關鍵詞表中關鍵詞的總數,降低了關鍵詞之間的混淆度,從而進一步提高了識別器的識別率。此外,對關鍵詞重要性進行了分級,不同的關鍵詞擁有不同的級別,對于重要的關鍵詞來說,只有在其置信度很高的情況下才會將其直接發送給硬件控制模塊去執行控制,否則要通過語音交互和用戶確認的方法來確定是否執行該命令。
針對不同的識別器,采用不同的自適應策略:由于噪聲模型和系統當前所處狀態直接相關,因此隨時準備利用系統空閑狀態時采集的噪音段對噪聲模型進行更新;對于孤立詞和連接詞識別引擎所采用的聲學模型來說,利用經過確認的語音段對相應的模型進行更新;對連續語音來說,由于只有對關鍵詞的置信度評價,很難保證非關鍵詞語音識別的正確性,因此只對關鍵詞模型進行更新,在用戶空閑時,引導用戶利用給定的語音輸入對連續語音所采用的模型進行更新,以達到模型自適應的效果。
4 實驗及結果分析
本文所采用的試驗平臺是用于連續語音電梯控制聲控仿真系統的關鍵詞檢出系統。整個系統由四個部分組成:語音識別模塊、語音確認模塊、自適應模塊以及對話管理模塊。語音識別模塊采用的是無跨越從左向右的CHMM模型,特征向量為39維的MFCC特征——12維的MEL特征系數以及一階和二階差分;能量及其一階和二階差分。確認模塊采用的是基于多特征聯合得分的確認算法[2]。
論文中所采用的語音數據庫包括三種類型:孤立語音——對應系統中采用的關鍵詞命令;連續語音——每段語音中包含一個相應的關鍵詞命令;含噪聲段的孤立語音——在關鍵詞命令對應的語音前后有一小段高能量突發噪聲。另外,把這三種類型的語音混合起來得到了混合語音數據。系統中采用的關鍵詞包括:公用的關鍵詞——打開,關閉,是,否;用于電梯控制的關鍵詞——上升,下降,一層,二層,三層,四層;用于輪椅控制的關鍵詞——前進,后退,停止;用于電視控制的關鍵詞——向上,向下,一臺,二臺,三臺,四臺,五臺。對于不同識別引擎以及不同語音數據,識別器的識別率以及系統的關鍵詞檢出率如表1所示。
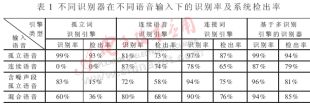
通過以上的實驗可以看出:對于三種不同的語音輸入,采用單一的識別引擎,不可避免地使得在某一種或幾種語音輸入下識別器的識別率以及系統的檢出率較低,極大地影響了系統的控制性能。當采用基于多識別引擎的識別器時,在任一語音輸入類型下,無論是識別率還是檢出率都能夠達到使用單一識別器時最優的效果。由此可見,在采用基于多識別引擎的識別器時,能夠充分利用不同識別引擎的優勢,使得系統的性能得到最大的提升。
本文針對傳統的單識別引擎在家電語音控制中存在的問題,提出了基于多識別引擎構造語音識別器的方法,使得對于不同類型的語音輸入,都能夠得到較好的關鍵詞檢出效果,從而提高了系統的性能;同時,本文對語音控制系統中關鍵詞確認、對話控制策略以及模型自適應技術進行了一定的分析和討論,并且搭建了完整的語音控制系統。目前本系統已經通過了日本富士通公司的檢測,其相關硬件的研制工作正在進行當中,有望在近期取得聯調成功。
參考文獻
1 Dai Hai-sheng,Zhu Xiao-yan,Luo Yu-pin, Yang Shi-yuan. Robust Edge Eetection Method for Speech Recognition. ICSP, 2004
2 Dai Hai-sheng,Zhu Xiao-yan,Luo Yu-pin, Yang Shi-yuan.An Utterance Verification Algorithm in Keyword Spotting System.IbPRIA, 2005