
在FPGA 上設計一個高性能、靈活的、面積小的通信體系結構是一項巨大的挑戰。大多數基于FPGA 的片上網絡都是運行在一個單一時鐘下。隨著FPGA 技術的發展,Xilinx 公司推出了Virtex-4 平臺。該平臺支持同一時間內32 個時鐘運行,也就是說每個片上網絡的內核可以在一個獨立的時鐘下運行, 從而使每個路由器和IP 核都運行在最佳頻率上。因此適用于設計多時鐘片上網絡,實現高性能分組交換片上網絡。
1 多時鐘片上網絡架構的分析
片上網絡結構包含了拓撲結構、流量控制、路由、緩沖以及仲裁。選擇合適網絡架構方面的元素,將對片上網絡的性能產生重大影響。
(1)網絡拓撲:在設計中,選擇Mesh 拓撲結構。Mesh結構擁有最小的面積開銷以及低功耗的特點。此外,Mesh 的線性區的節點數量規模大以及通道較寬。同時,Mesh 也能很好地映射到FPGA 下的底層路由結構,降低了FPGA 邏輯擁塞和路由器的功耗。
(2)流控機制:虛擬直通和蟲洞技術(不像存儲轉發)有數據包的延時與路徑長度成正比。然而,與復雜的蟲洞路由器相比, 虛擬直通的路由器更加適合于設計的實現。因此,選擇虛擬直通流量控制機制作為路由器的流量控制機制。相比較蟲洞機制,它能支持更高的吞吐量,在堵塞時能更有效地釋放緩存。此外,虛擬直通流量控制低延時的高信道利用率, 與此同時并不保留物理通道。
(3)路由算法:選擇XY 算法作為設計所采用的路由算法。該算法中分組的路由只取決于源節點和目的節點的地址,而與網絡狀況無關。當使用算法時首先在X 維上進行路由,當到達與目的節點同一列時,轉向在Y 維上的路由,最后到達目的節點。該算法對硬件要求簡單和實現容易, 在網絡流量不大時, 具有較小的時延,能夠有效避免死鎖和活鎖。
(4)仲裁機制:輸入端口分配是基于簡單的Roundrobin[3]機制。上次接收或解決接收的端口會放在隊列的末端。切換時到下游的數據包。當交換數據包時,FIFO的虛擬通道也遵循這種機制。
2 路由器微節點結構的設計
多時鐘片上網絡的路由器由5 個輸入端口、交叉點矩陣和中央的仲裁器三部分組成。除了頭譯碼邏輯,5 個輸入端口都是相同的。由于設計中采取了虛擬通道流控機制(VCS),因此輸入端口就必須包含仲裁邏輯。與此同時, 輸入端口還應包含輸入緩沖區來存儲輸入的數據包。
2.1 數據包
利用Xilinx block RAM, 設置深度為16 的FIFO(先入先出隊列),數據包的大小能在24 位與128 位之間變化,每個數據包HEADER(包頭)占用一個flit(數據片)。flit 的大小固定在8 位。數據包頭包含路由目標地址、flit 的類型以及部分數據包。設計中采用的虛擬直通流量控制需要1 位去指定數據片的類型。路由器支持可變化大小的數據包, 通過編碼將數據包的大小編譯為字段,作為bRAM 所需要的部分,放在數據包頭部。每個IP 核的網絡接口(NI)起到存儲在數據包頭部的信息的作用。當需要更高粒度數據包時,部分數據包的位數以及寬度將會相應的增加。增加部分數據包的位數的同時也提高了緩存的利用率。數據包首部保留的位數將用于實現基于優先級的流量控制。
2.2 輸入端口
路由器有5 個輸入端口, 通過端口分別與內核及鄰近的路由器通信, 這5 個端口按在方位可分為本地(L),北(N),東(E),南(S),西(W)。每個輸入端口可以支持虛擬通道多路復用,相關聯的仲裁器,以及頭譯碼邏輯,從而作出路由決定。如圖1,輸入端口的3 個主要組成部分分別是虛擬通道選擇器、FIFO bRAMs 以及bRAM 仲裁器。虛擬通道選擇器:決定輸入端緩存的使用空間的決定權在虛擬通道選擇器。當數據包大小以編碼形式傳播時,虛擬通道選擇器接收數據包的首部。當虛擬通道選擇器收到來自上游路由器或者來自自身核心的數據時, 虛擬通道選擇器就會拿數據包的大小跟虛擬通道目前可以容納數據包的大小進行比較。這么做的目的是為了能夠使輸入的數據能夠符合FIFO 中write_count 的大小。如果有足夠的空間存在,則虛擬通道選擇器將同意輸入請求, 同時反饋信息。在此過程中,虛擬通道選擇器還設置了輸入端解復用器。解復用器的作用是使數據包從輸入通道傳輸到正確的復用器的輸入緩存中。FIFO bRAMs:在所設計的路由器中,緩沖區的深度將參數化,在試驗時同時將其深度設置為16 。這些緩存區將被作為bRAM FIFO 的存儲器,同時起到以下作用:
(1)緩沖部分或者全部到來的數據包,以及當下游開關可以用時,傳送頭部及緊跟的flit。
(2)劃分路由器核心以及路由器的頻率,從而支持一個多時鐘的網絡設計。
(3)通過仲裁器監察write_count 端口的信息,來實現支持可變化大小的數據包。在緩沖區有單獨時鐘域的情況時, 就需要一種有效的方式實施完整的或者空的邏輯。通過以下方式使控制信號同步:
(1)發送數據包粒度作為一小部分FIFO 的空間。
(2) 在一個時鐘周期內, 一個連接終止之前設置flit 的尾部位。在所使用的FPGA 設計中,由于支持FIFO 的最小深度是16, 所以它適合于在虛擬直通中緩沖整個數據包。write_count 的空和滿狀態信號將集成在FIFO 中。在一個多數據包的緩沖區中加大存儲flit 的能力,將有助于提高FIFO 的利用率。此外,獲得網絡的吞吐量的增益,是由于上游連續包釋放緩沖區所促成的。
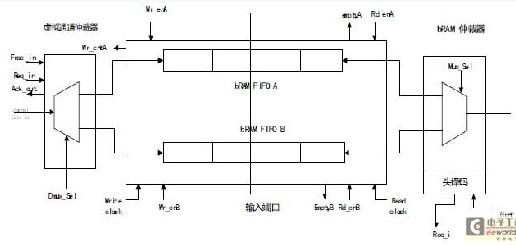
圖1 輸入端口設計圖
bRAM 仲裁器: 輸入端口還包含了控制邏輯作出的仲裁決定。當選擇一個非空的bRAM 時, 簡單的Round-robin 的方式仲裁算法將會啟用。當選擇bRAM時,FSM 將會送出頭部flit,解碼出它的目的地址,并發送相應的要求。在所設計的路由器中采用XY 路由算法將大大簡化了解碼器的邏輯結構。根據XY 路由算法的通行路徑許可,即將釋放的請求線將會減少。
頭譯碼器:在XY 路由算法中,頭數據片一開始往X 軸方向走,當到達X 軸所在的目標地址時,就會往Y方向走。所有緊隨著的數據片將以流水線的方式跟著頭數據片移動。這種簡便的XY 路由算法適用于減化頭解碼器、交叉點矩陣以及中央仲裁器的邏輯結構。以上簡化得邏輯結構將使FPGA 的芯片數顯著減少。
2.3 交叉點矩陣
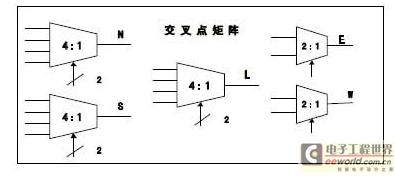
設計一個多路交叉點矩陣, 目的是為了減少面積的使用。而另一種設計是支持復分解虛擬通道的交叉點連接。后一種方法,產生高網絡吞吐量,但要增加一個重要的復雜性開關。交叉點支持并行連接,以及被用于通過中央仲裁器支持多個信號同時請求。并非所有的交叉點連接都是使用XY 路由算法。經過邏輯優化,如圖2 所示設計中實施簡單的4 和2 輸入多路復用器開關(分別是L、N、S、E 以及W 端口)。上述優化方案減少了交叉點面積,使其使用的切片只有32 片。因此,達到路由器面積顯著減小的目的。
輸入端口的分配方式將采用簡單的Round-robin仲裁機制。對上一次接收過的或沒有用到的端口將給予最低優先級,并排在隊列的最末端。將通過以下的方式提高路由器的性能:
(1)降低中央仲裁器的邏輯復雜度;
(2)盡量集中仲裁器,以減少req/grant 信號的數量。
在設計中減少邏輯復雜度以及布線, 從而減少數據堵塞,達到提高性能以及減低功耗的效果。
3 性能分析
利用Virtex-4 系列中XC4VLX100-11[4]設備進行設計, 利用Xilinx ISE 8.2i 進行綜合布局布線。使用ModelSim 6.1c[5]驗證所設計的功能。設置了單一時鐘和多時鐘進行了模擬,分析多時鐘片上網絡的性能。由于路由器是直接連接到內核, 所以沒必要考慮片與片之間的延時而去估計最高的頻率。所設計是由一個路由功能模塊(RFM)執行[6],用以準確地估計工作頻率,基本路由器的單機版工作頻率可到達357MHz。因此8bits 通道的路由器的吞吐量最高可達2.85Gbits/s。在所設計的路由器中, 頭數據片前進到下一個節點,而剩下的數據片以流水線方式流通。在計劃中,網絡延時僅僅與路徑長度H(跳躍點數量)有關。在信道爭用的情況下,網絡延時L 可以用以下方式計算:
L = 7×H + B/w (1)
公式(1)中,B 是數據包的字節數,w 是每個時鐘周期轉換的字節數。參數7 是在多時鐘片上網絡路由器中安裝在每個路由器跳延遲支付。這個延時是因為基于數據包中的頭數據片的解碼和仲裁執行所導致的。
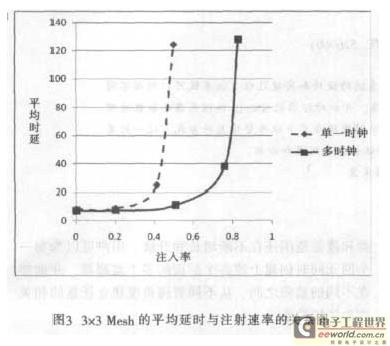
本文介紹了一個基于FPGA 的高效率多時鐘的虛擬直通路由器,通過優化中央仲裁器和交叉點矩陣,以爭取較小面積和更高的性能。同時,擴展路由器運作在獨立頻率的多時鐘NoC 架構中,并在一個3×3Mesh 的架構下實驗,分析其性能特點,比較得出多時鐘片上網絡具有更高的性能。